
For the text analysis assignment, I initially attempted topic modeling using Mallet, but after many failed attempts, error messages and hair-pulling, I decided to switch gears. I chose to work with Voyant, especially after trying Mallet, because I felt it was the easiest to maneuver and offered a variety of tools for analyzing the data.
My dataset consisted of transcripts from three parliamentary debates that occurred in Britain during the year of 1944. These debates, which took place in March, June and November of that year, discussed three white papers that outlined the government’s policy plans for the creation of a welfare state in Britain. In these debates, Members of Parliament (MPs) discussed the creation of a national health service, employment policy, as well as the establishment of a scheme of social insurance and a system of family allowances.
I chose this dataset because it made up a large portion of the primary source material I used to write my history honors thesis that explored the origins of the British welfare state. For my thesis, I read and analyzed these debates to understand how MPs discussed the establishment of a welfare state and their motivations for its creation. I found the miseries experienced in the aftermath of WWI, the desire to maintain superiority within the world order, and anxieties surrounding the future of the ‘British race’ spurred the call for a welfare state that benefited all Britons. Only through close reading did I discover these motivations and causations.
For this assignment, I thought it would be interesting to use Voyant to conduct a distant reading of these debates to see what appeared significant. I started by inserting each debate as a separate document. From the initial output, I saw I needed to add some addition stop words to the automate list. Words like hon, mr and member related to MPs addressing each other in the discussions. The words, white, scheme, paper referred back to the physical documents being discussed. I decided to add these words to the stop-word list because I believed they skewed the results.
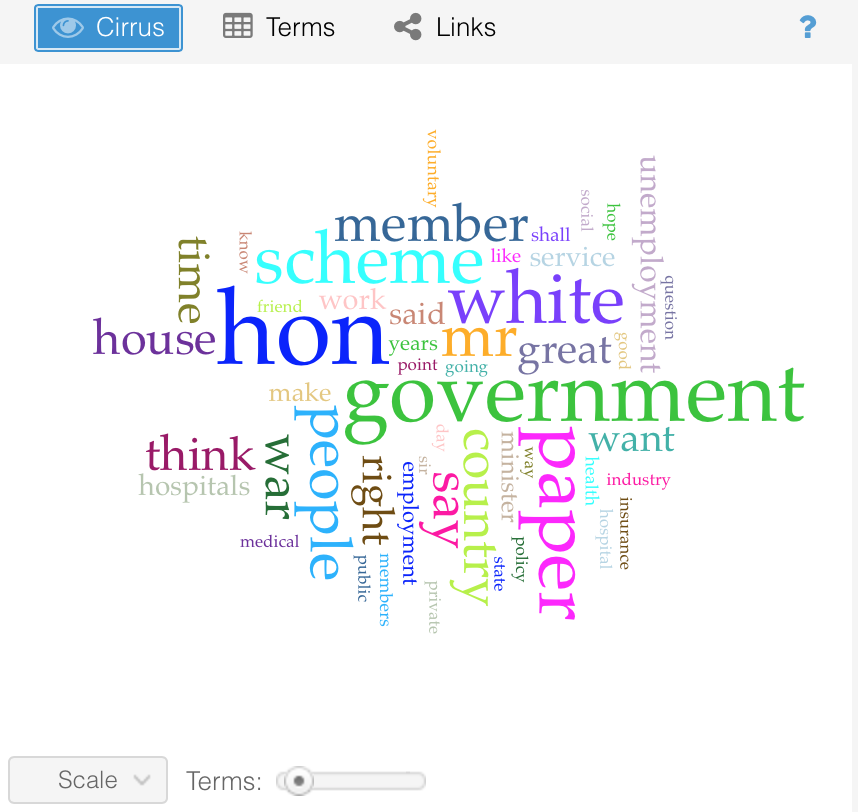
After adding to the stop-word list I reran Voyant to update my results.

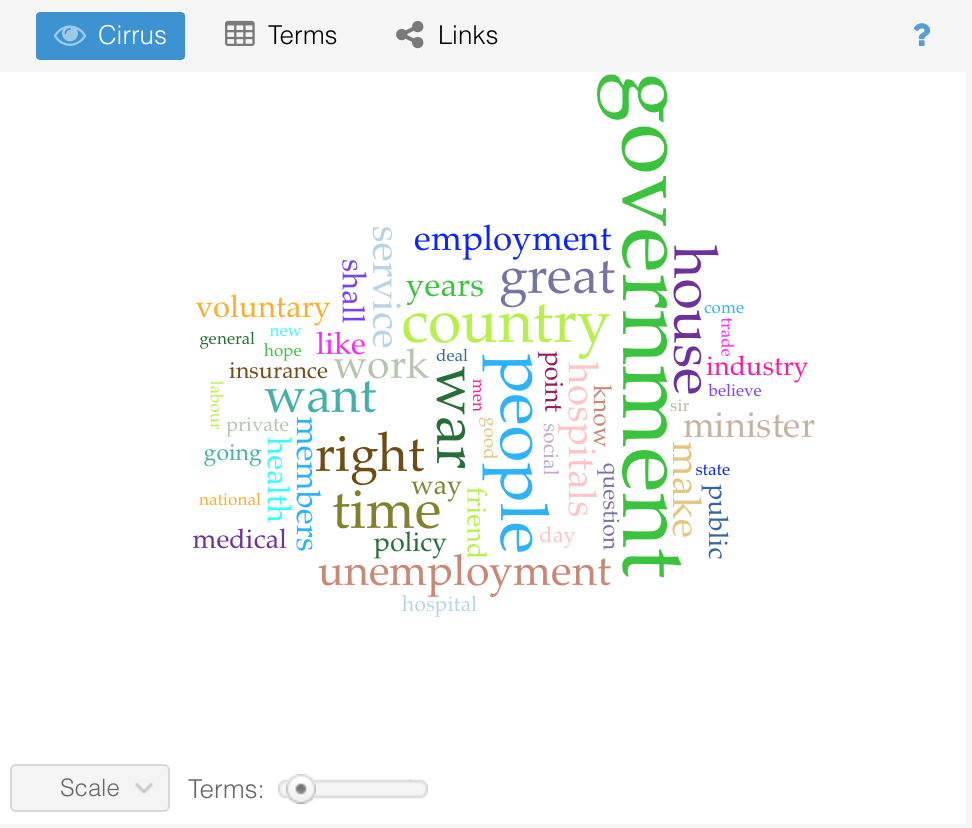
The five words that occurred the most in theses debates were, in order, government, people, country, war and right. These words, to me, were not surprising; they corresponded to the content of the debates. MPs discussed the government’s role in providing welfare to the people, how the country would benefit from its creation and believed it was the right thing to do for the entire population. The word link images below further illustrate word connections within the corpus.
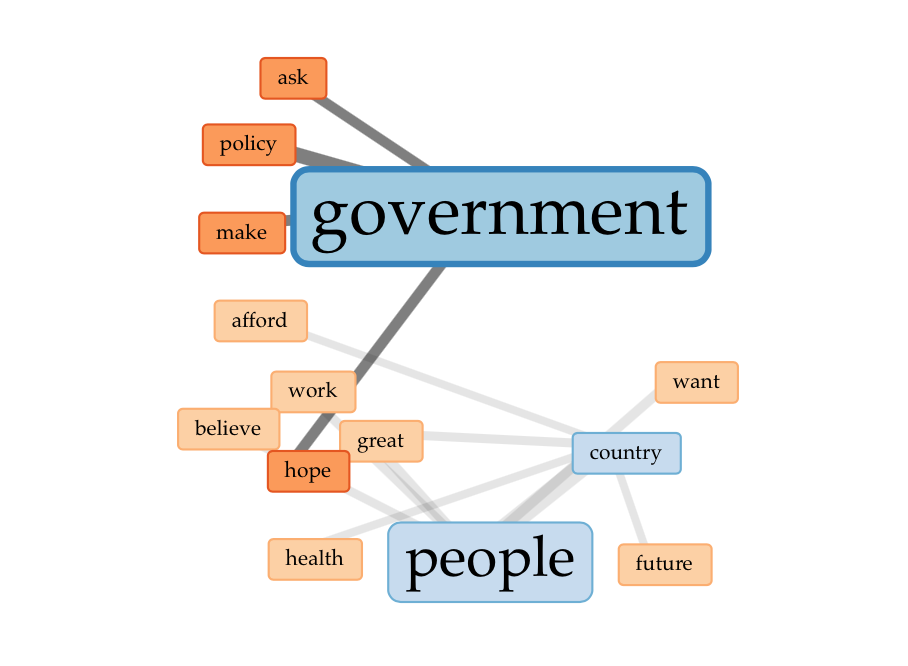
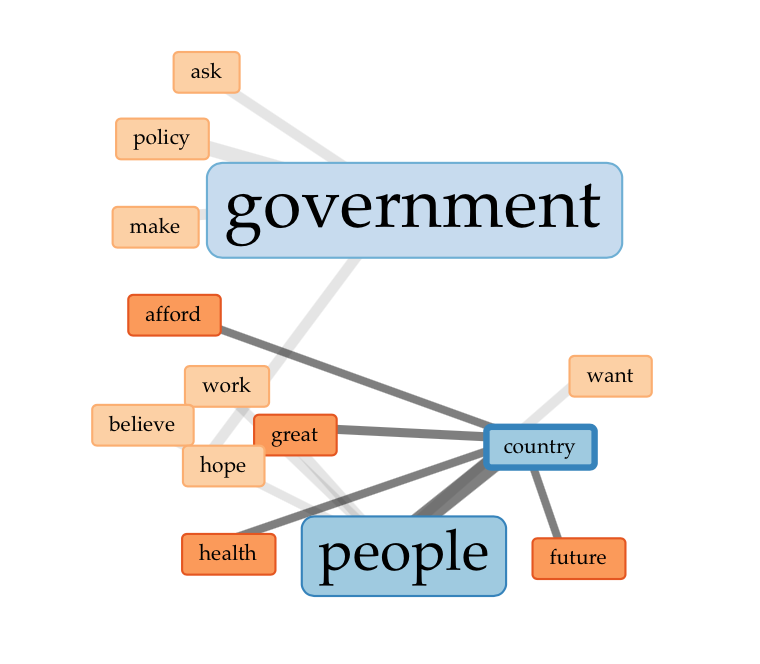
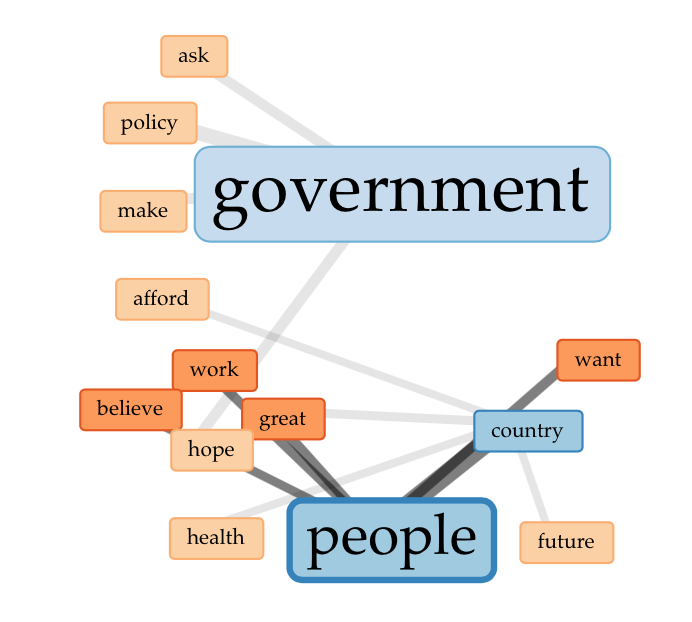
These three images show how the top words government, country and people correspond to other words found within the documents. For someone who has not close read the debates it might be difficult to pull meaning from these connections. From my close reading, these links reflect main points from the corpus: there was great hope in the government’s ability to make policies that addressed the people’s needs and a strong belief that from these policies the country’s future and health would benefit.
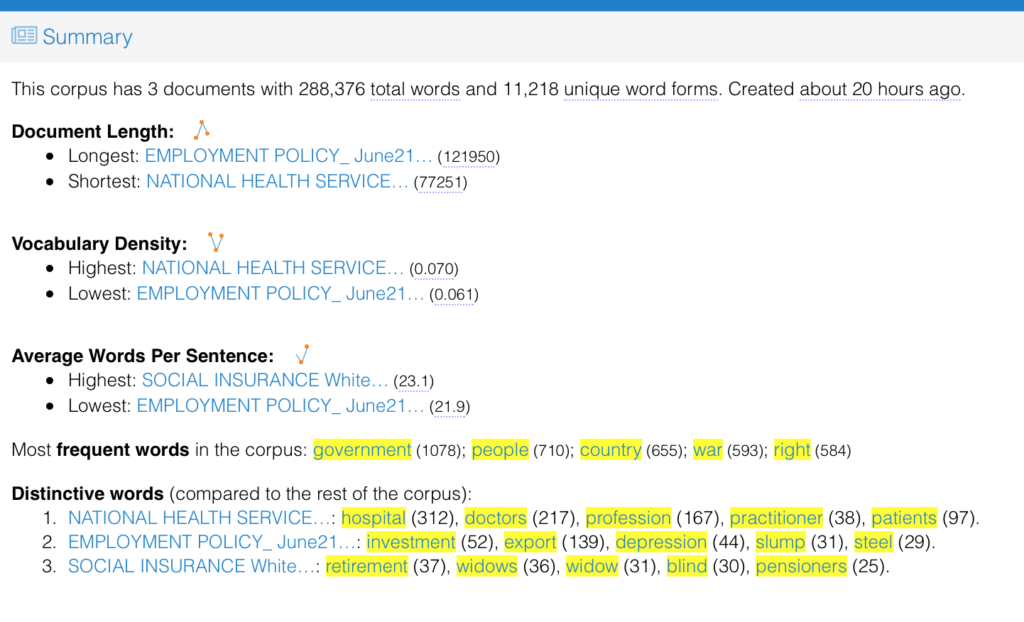
When looking at the summary of the corpus below, the distinctive words within each documents reflect the themes of each. Without knowing the title or topics of each debate, I believe an individual could make an educated guess of what each document details. I think this tool could be useful when trying to determine the contents of a large number of documents within a corpus. Because there are only three documents with rather distinct topics, it is easy to determine the overall contents.
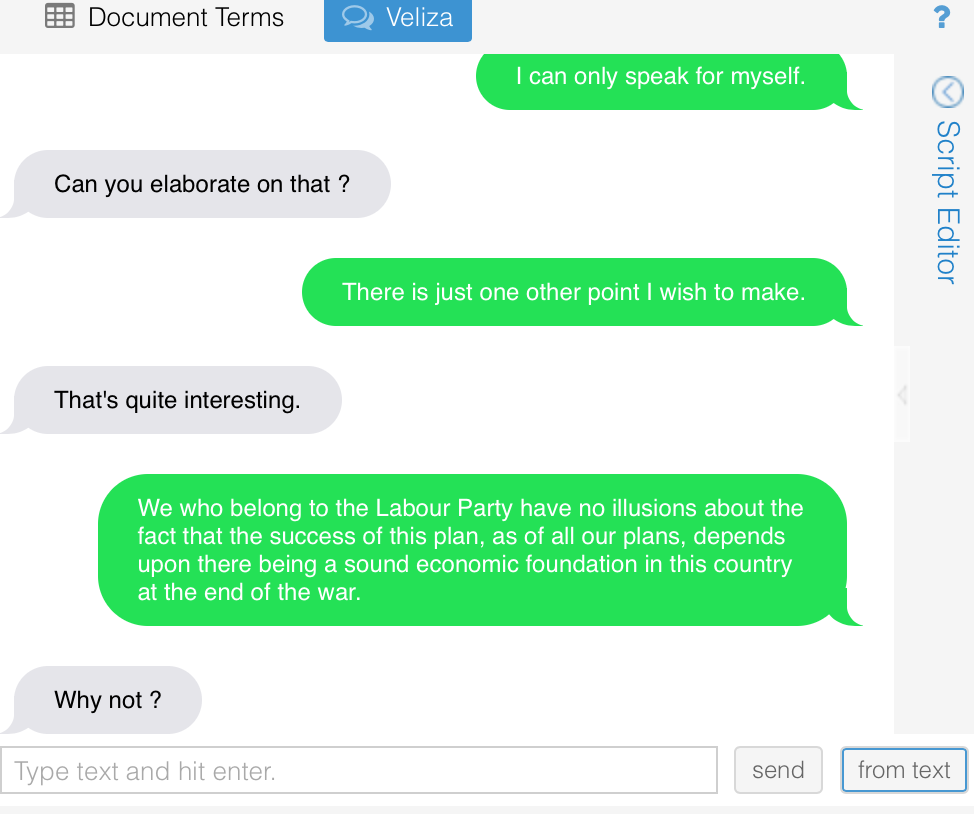
I spent some time exploring the other tools offered through Voyant that aren’t initially displayed on the dashboard. While going through the additional offerings, I found some to be useful toward my data and others that were not. One tool that I found interesting was Veliza. According to the Voyant Help page, “Veliza is a (very) experimental tool for having a (limited) natural language exchange (in English) based on your corpus”. It is inspired by the Eliza computer program that mimics the responses of a Rogerian psychotherapist. I didn’t know the context of either, so after googling I found the basic premise was that the computer program would respond to your text in a way a psychologist typically would.
To start, you can choose between entering your own text, or text from you corpus you wish to discuss, into the text bubble at the bottom to start a conversation. Or you can import text from your corpus by random using the ‘from text’ button. I chose to use the button to randomly enter text to see how the tool would respond. I clicked the ‘from text’ button multiple times to see the variety of responses. Below is a example of a conversation with text from my corpus. Even though this tool is not specifically useful for analyzing data, it was fun to play around and test how Veliza would answer.
Final Thoughts
It is always important to remember the parameters of analysis are set by the researcher when doing any type of text analysis. With my analysis, I chose the documents as well as additional stop-words added to the list. This created a specific environment for exploration. Another individual could do an analysis of these documents and come to very different conclusions based on how they framed the data. I believe my close reading of the documents influenced my distant reading of them. My knowledge of the context gave me a better understanding of the distant reading results. Or one could also say, influenced my understanding of them because I already had preconceived notions. In general, I think distant reading is usually better with a large corpus, allowing for patterns to be discerned over time, but I was excited to see how the data I had spent so much time examining up close would look from afar, so to speak.
Overall, I think Voyant is a good way to get a broad analysis of a corpus or document. With the variety of features available, this tool is helpful when an individual wants to look at the data from multiple directions. Not being limited to only word links or topic modeling allows for wider exploration of a corpus and a higher likelihood that some type of insight will be gleaned from the first iteration of analysis.
In the future, I think it would be an interesting project to look more broadly at British parliamentary debates over time to see if any interesting patterns appear. The website Hansard has the official reports of parliamentary debates dating back 200 years and gives users the option to download debates into a plain text file, making the analysis of these debates with computational tools quite easy.