
For my text analysis project, I decided to build two corpora each based on a political doctrine of imperialism.
This is the first text analysis project I’ve undertaken so I want to make clear that the goal of this analysis is experimentation. I am not attempting to draw any finite conclusions or make general comparisons about the historical events which give context to these corpora. The goal is to explore the documents for topical parallels and reciprocity of language simply based on the texts; and hopefully have some fun while discovering methods of text analysis. Nonetheless, I am aware that my selection process is entrenched in biases related to my epistemological approach and to my identity politics.
When I began this project, I was thinking broadly about American Imperialism. I was initially building a corpus for exploring the rise of American imperialism chronologically starting with the Northwest Ordinance to modern day military and cultural imperialism through digital media. The scope of the project was simply too massive to undertake for this assignment, so I started thinking more narrowly about Manifest Destiny. I started thinking about the Trail of Tears, and as I did, my mind went back and forth to parallels of the Death Marches in Nazi-Occupied Europe. So I thought; why not build two corpora to reflect the two imperialist doctrines which contextualize these events. Manifest Destiny and Generalplan Ost.
Manifest Destiny Corpus
The following bullet points are the notes that best sum up my selected documents for Manifest Destiny.
- U.S Imperialist doctrine of rapid territorial expansion from sea to shining sea.
- Territorial expansion will spread yeoman virtues of agrarian society
- Romanticization of rugged individualism on the frontier
- Removal and massacre of inhabitants of desirable lands.
- Racial superiority over native inhabitants.
- Territorial expansion is intended by divine Providence.
Generalplan Ost Corpus
The following bullet points are the notes that best sum up my selected documents for Generalplan Ost.
- German Imperialist doctrine of rapid territorial expansion across Eastern Europe.
- Territorial expansion will create an enlightened peasantry
- Romanticization of nationalistic racial purity as patriotism
- Deportation and genocide of inhabitants of desirable lands.
- Racial superiority over Jews, Slavs, Roma, and non-Aryans.
- Territorial expansion is justified by WWI’s illegitimate borders.
Building the corpora
Building the corpora was one of the most time-consuming processes of the analysis. Prior to selecting my documents, I identified some important criteria that I felt were necessary for a balanced representation of voices. I wanted to incorporate both doctrinal and anti-doctrinal perspectives, both primary and secondary sources, as well as temporal distance in the categories of contemporaneous and non-contemporaneous. I used a triage table to sort documents. Here are a few examples;
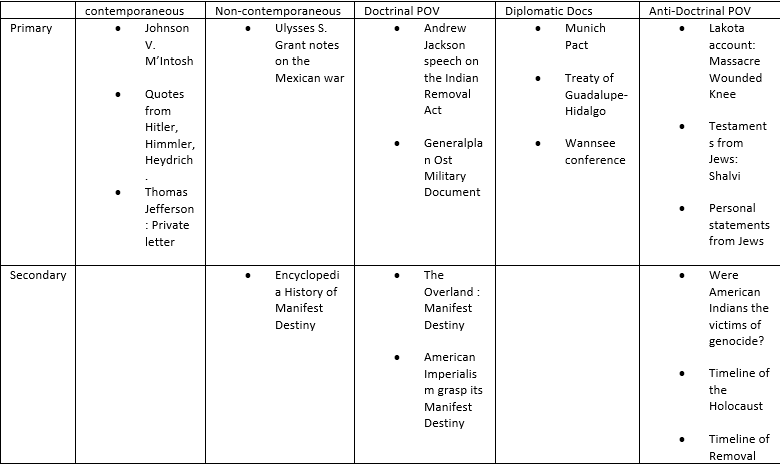
Once I had selected ten documents for each corpus, I was faced with what seemed to be the insurmountable task of tidying the data. Several documents were in German. I had all types of file objects, some web-pages, some PDFs, and some digitized scans. For the digitized scans which were mostly diplomatic documents, I was able to find a digitized text reader from the Yale Law Avalon Project which not only read the texts but translated them from German to English since it already had a matching document in its corpus. For the secondary source German document, I used the “translate this page” web option. I scraped all the web-pages using BeautifulSoup and converted all my documents into plain-text files for both corpora. By the end of my second day on the project, I had created 20 files on which to run some text analysis.
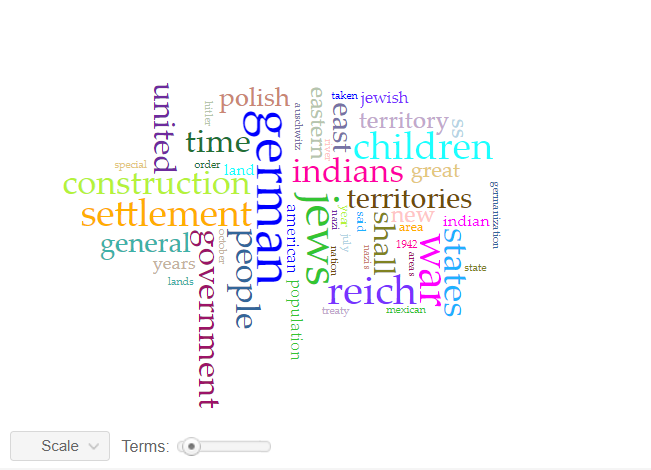
I was a bit nervous about building my own python notebook, so I started working with Voyant. At first, I uploaded each corpus into Voyant to analyze one by one. Not yet looking for parallels, I wanted to see what a distant reading of the selected documents would look like on their own. And immediately after loading my Generalplan Ost corpus, I was greeted with five mini windows of visualized data. The most remarkable one was the word cloud with terms such as; Reich, German, Jews, 1941 colorfully appearing in large fonts, indicating the lexical density of each term in the corpus. Similarly, with the Manifest Destiny corpus, terms such as; War, Indian, States, Treaty also appeared in a constructed word cloud. I found many interesting visualizations of the lexical content of each corpus, but my goal was to bring the whole thing together and search for parallels in topics and reciprocity in the language.
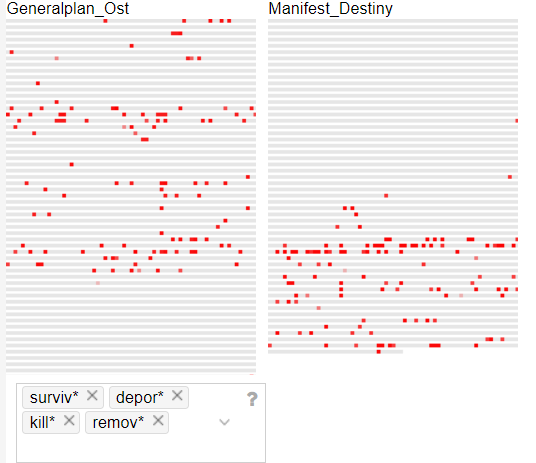
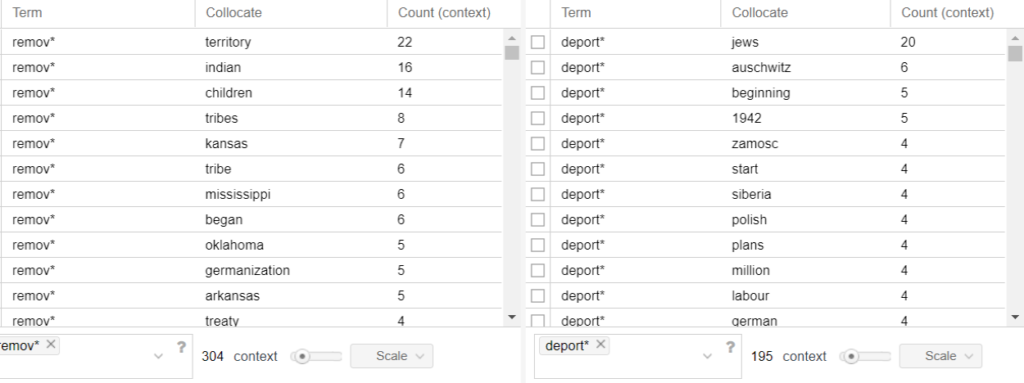
I brought the two corpora together and started digging. One of the best tools I found on Voyant is the MicroSearch tool which displays a selected term in its local occurrence (where it is found) over the entire corpora. It displays lexical density in context as a miniaturization of the original text format and not as an abstract visualization. It is tantamount to geotagging items on a map. You can look at the map and see where each item is located in relation to other items. I found this tool incredibly effective at displaying parallels across corpora. For example, in this MicroSearch capture, I was looking for the terms with the following root words (surviv*, deport*, kill*, remov*) indicated by (*). The MicroSearch returned all instances of all words with the roots I selected wherever they were found. As a result, I was able to visualize a key topical parallel in the corpora; the term removal being frequent in relation to Indian, and the term deportation being frequent in relation to Jewish.
This capture is a MicroSearch of the terms with the following root words (terri*, empi*, imperi*, land*, settl*, colon*, constr*)
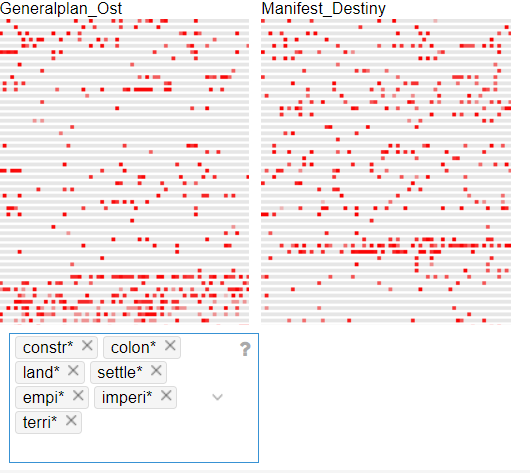
If I were to group these root words into the topic of ‘imperialism’. I could make the case for a topical parallel based on the lexical density and distribution of those terms in the corpora.
Another tool that I found useful was the collation tool. The collation tool matches words that repeatedly appear next to each other and counts the frequencies at which they occur. Matching two words allows for each word to frame the context of the other and the higher the frequency number, the stronger the relationship is between those words. For example, in this capture, the term deport* and the term Jews are found together 20 times. Whereas the term remov* and the term Indian occur together 16 times.
The crossing bars in the trend graph represent a reciprocal relationship between the terms Jew: Indian. The term Jew* appears 306 times in the Generalplan Ost corpus which is comprised of 45495 tokens. I can determine the numerical value of its lexical density as follow; 306/45495 = 0.00672601 which in percentage equals 0.673%
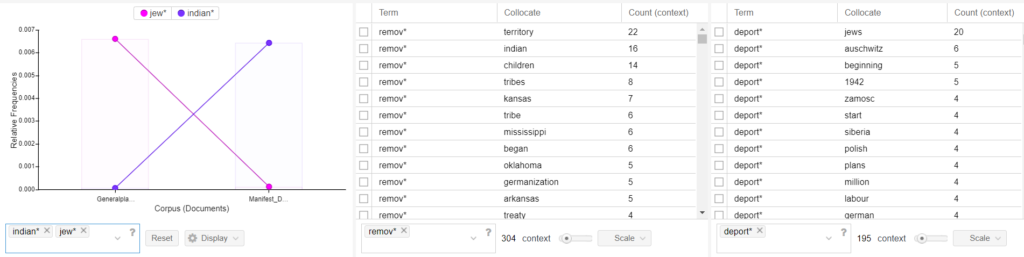
The term Indian* appears 257 times in the Manifest Destiny corpus which is comprised of 39450 tokens. 257/39450 = 0.00651458 which in percentage equals 0.651%.
While I experimented with Voyant, I became aware of the limitations of its tools. And I started to think about building a python notebook. I was hesitant to do so because of my limited use of python and the complicated syntax that easily returns error messages which then takes extra time to solve. Despite my hesitance, I knew there was much more in the corpora to explore and after spending an hour parsing through the notebook with Micki Kaufman, I felt a little empowered to continue working on it. The first hiccup happened in the second line of code. While I was opening my files, I ran into an UnicodeEncode error which was not a problem for a web-based program like Voyant. I had saved my German texts using IBM EBCDIC encoding. I had to go back and save everything as UTF8. It took me reading about a chapter and a half of the NLTK book to figure out that I could not do a text concordance, or a dispersion plot from a file that was not a text.text file. But once I was able to learn from those errors, I was excited at the possibility to discover so much more using python.
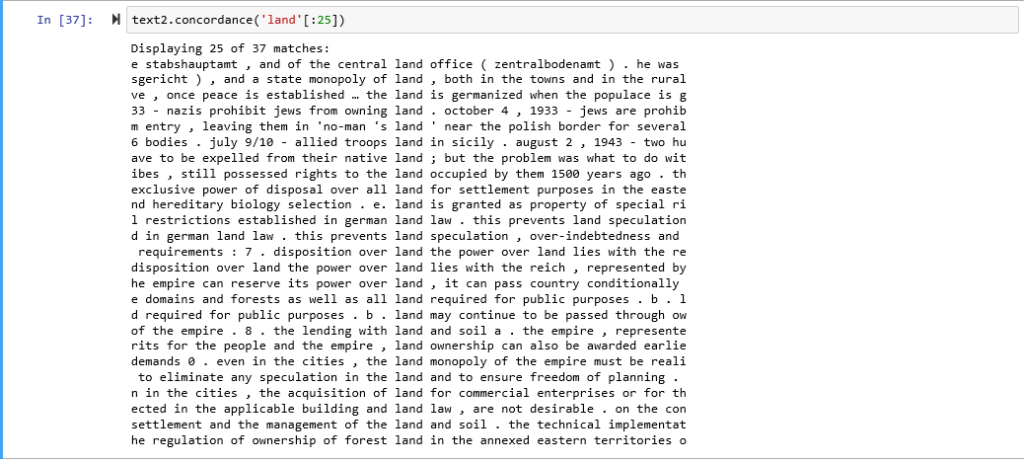
Here I created a concordance with the Generalplan Ost corpus for the word; land
(A text concordance centralizes a selected term within a text excerpt that surrounds it to give context to the term.)
Look at the key words surrounding the word land in this instance.
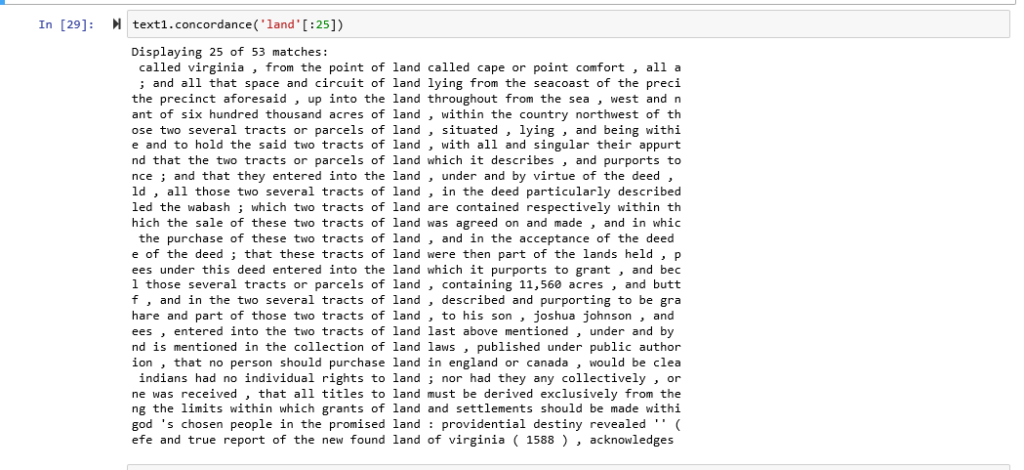
Here I created a concordance with the Manifest Destiny corpus for the word; land
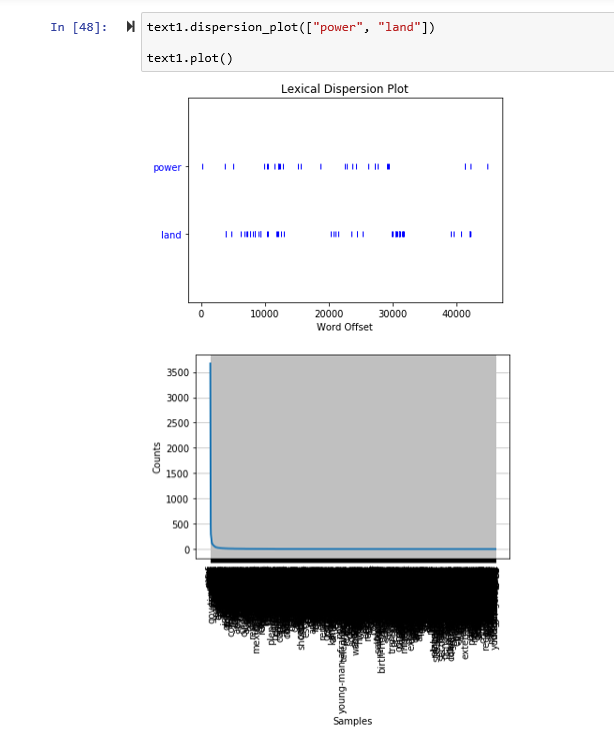
Here I created a dispersion plot with the Generalplan Ost corpus for the words; power: land

Here I created a dispersion plot with the Manifest Destiny corpus for the words; power: land
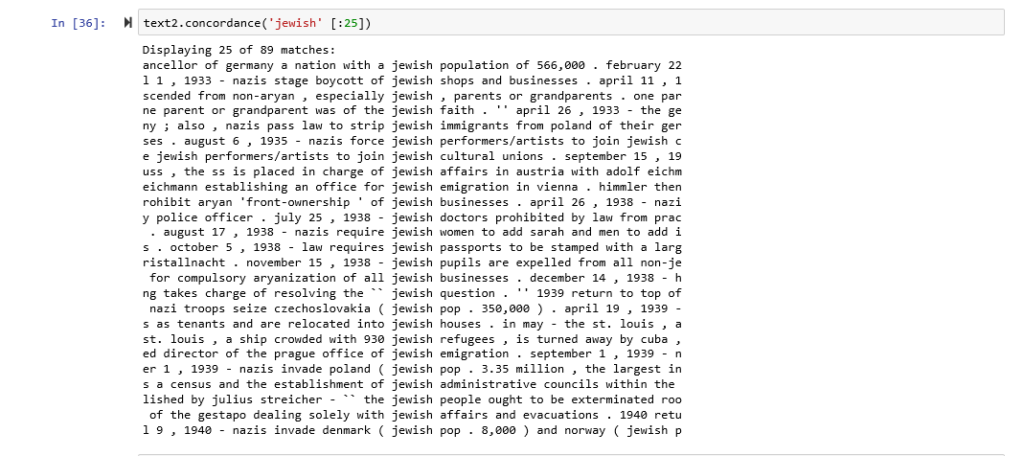
Here are concordances for the terms Jewish: Indian
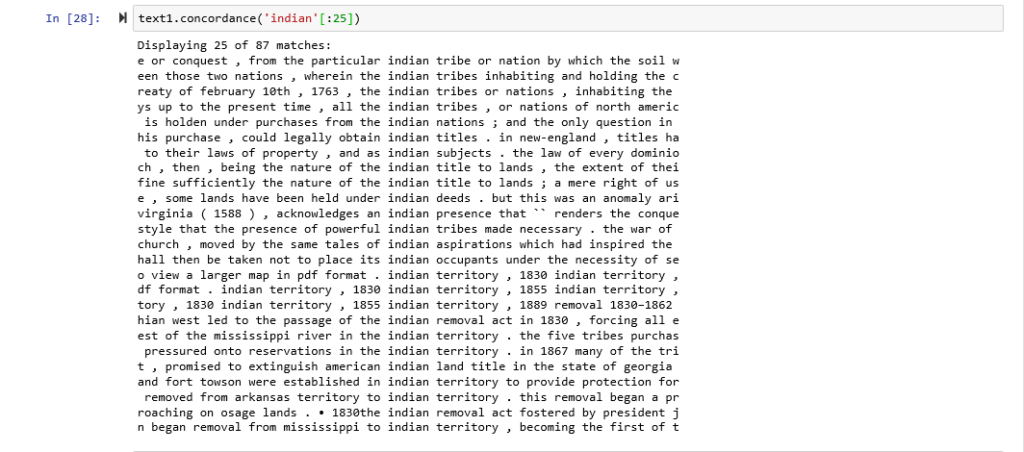
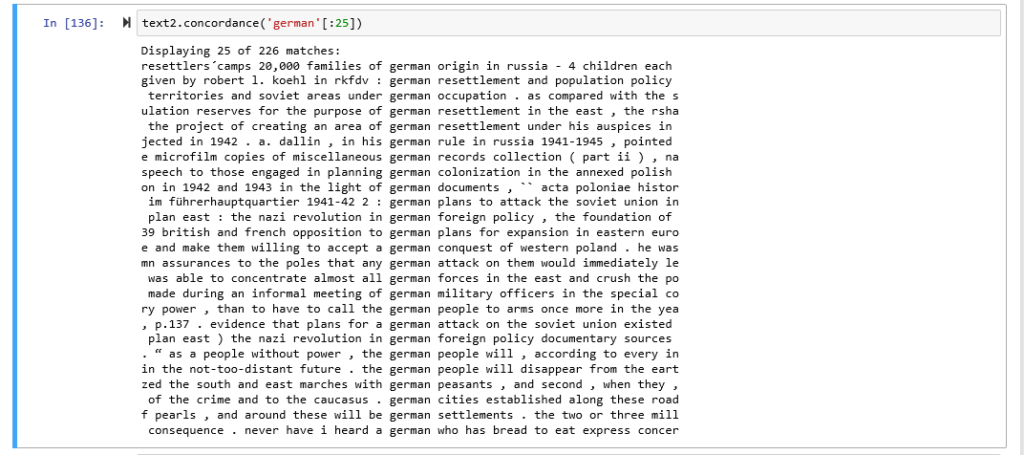
Here are concordances for the terms American: German

Although I can enumerate many parallels in the corpora. There were some distinct differences that I found.
For example, in Voyant, words that appeared in large fonts in the word cloud in the Generalplan Ost corpus such as Reich and German, and to a lesser degree Hitler and Himmler were highly correlated to the doctrinal perspective which makes me think that in spite of my efforts at representing as plural a selection of voices as I could find, the documents I selected for their contextual importance still overwhelmingly represented the doctrinal perspective. In the Manifest Destiny corpus, I noticed that words such as; war, Indian, states, and shall, were the most frequently distributed. I wonder if United States being two words instead of one and being often abbreviated to U.S or America contributed to a lexical density split. In addition, the Manifest Destiny corpus beside having the same number of documents as the Generalplan Ost corpus contained 6, 045 fewer tokens.
Here are some general data from my python notebook
| Corpus | Total tokens | Unique tokens | Lexical density % | Most unique words |
| Manifest Destiny | 39450 | 6201 | 13.80% | Indian, treaty, Mexican, destiny, deed |
| Generalplan Ost | 45945 | 6216 | 12.05% | Reich, polish, ss, germanization, 1942 |
Here are some additional captures from Voyant and python that are also interesting.


I am bowled over, Margael, by the scope of your work here. Your premise is fascinating, and, even with the biases and limits of your corpera that you acknowledge from the start, you tease out some intriguing areas for further investigation. The dispersion plots are particularly compelling, as they visually wed land to power both within each corpus and across the century that divides the doctrines. I’d love to compare our codes right before or after our 12/4 class, if you’re game. I’d love to see if we built our programs similarly (as our results suggest we did). I’m grateful that you included some of your code in the screen shots so I can try the concordance view myself!