
This project aims to make some meaning from over a quarter million text messages exchanged over the course of a 6+ year relationship. It is an extension of a more qualitative project I began in 2017.
Here’a a recap of Part I:
In the spring of 2017, I was a senior in college. My iPhone was so low on storage that it hadn’t taken a picture in almost a year, and would quit applications without warning while I was using them (Google Maps in the middle of an intersection, for example). I knew that my increasingly lagging, hamstringed piece of technology was not at the necessary end of its life, but simply drowning in data.
The cyborg in me refused to take action, because I knew exactly where the offending data was coming from: one text message conversation that extended back to 2013, which comprised nearly the entire written record of the relationship I was in, and which represented a fundamental change in the way I used technology (spoiler: the change was that I fell in love and suddenly desired to be constantly connected through technology, something I had not wanted before). And in the spring of 2017, I didn’t want to delete the conversation because I was anxious about whether the relationship would continue after we graduated college.
Eventually, though, I paid for a software that allowed me to download my text messages and save them as .csv, .txt, and .pdf on my computer. (I also saved them to my external hard drive, because in addition to not knowing if my relationship would survive the end of college, I also had no job offers and was an English major and I really needed some reassurance.) So I did all of that, for all 150,000+ messages and nearly 3GB worth of [largely dog-related] media attachments. This is but one portrait of young love in the digital age.
I wrote a personal essay about the experience in 2017, which focused on the qualitative aspect of this techno-personal situation. Here is an excerpt of my thoughts on the project in 2017:
“I was sitting at my kitchen table when I downloaded the software to create those Excel sheets, and I allotted myself twenty minutes for the task. Four and a half hours later, I was still sitting there, addicted to the old texts. Starting from the very beginning, it was like picking up radio frequencies for old emotions as I read texts that I could remember agonizing over, and texts that had made my heart swell impossibly large as I read them the first time. …
I had not known or realized that every text message would be a tiny historical document to my later self, but now that I had access to them going all the way back to the beginning, they were exactly that to me as I sat poring over them. It was archaeology to reconstruct forgotten days, but more often than not I was unable to reconstruct a day and just wondered what we had done in the intervening radio silences that meant we were together in person. These messages made the negative space of a relationship, and the positive form was not always distinguishable in unaided memory. “
The piece concluded with a reminiscence of a then-recent event, in which a friend of ours had tripped and needed a ride to the emergency room at 3 in the morning. We were up until 5am and ended up finishing the night, chin-stitches and all, at a place famous for opening for donuts at 4 in the morning. The only text message record of that now oft-retold story is one from me at 3:45am saying “How’s it going?” from the ER waiting room, and a reply saying “Good. Out soon”. I concluded that piece with the idea that while the text message data was powerful in its ability to bring back old emotions and reconstruct days I would have otherwise forgotten, it was obviously incomplete and liable to leave out some of the aspects most important to the experiences themselves.
So now, Part II of this project.
I compiled a new data set, taken from the last two years of backups I have done with the same software (and same relationship — we have thus far lasted beyond graduation). I loaded the data into Voyant, excited to do some exploratory data analysis. The word cloud greeted me immediately, and I thought to myself “is this really how dumb I am?”
Okay, maybe that’s a bit harsh, but truly, parsing through this data has made me feel like I spend day after day generating absolute drivel, one digital dumpster after another of “lol,” “ok,” “yeah,” “hi,” “u?” and more. I was imagining that this written record of a six year relationship would have some of the trappings of an epistolary correspondence, and that literary bar is 100% too high for this data. See the word cloud below for a quick glimpse of what it’s like to text me all day.

Some quick facts about the data set:
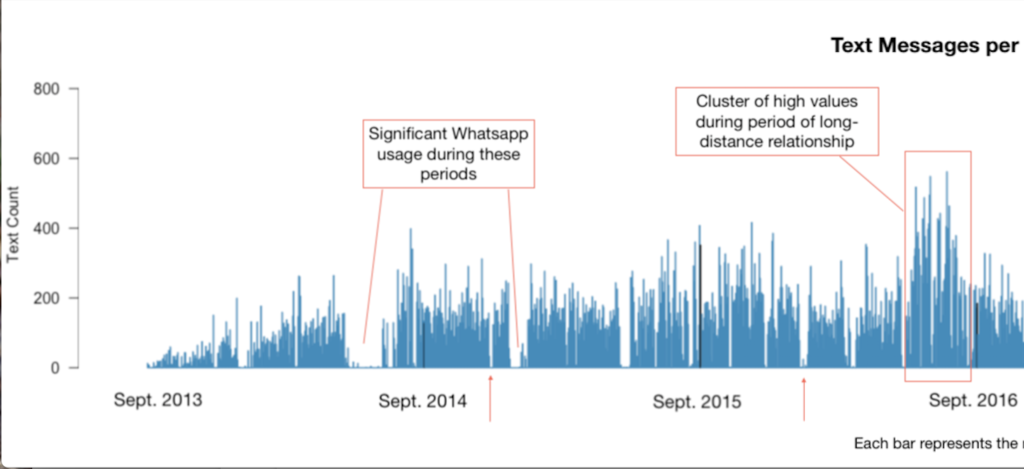
Source: all iMessages and text messages exchanged between August 31, 2013 and November 12, 2019, except a missing chunk of data from a 2-month lost backup (12-25-18 to 03-01-18). *****EDIT 11/19: I just found it!! iMessages switched from phone number to iCloud account, so were not found in phone number backup. Now there are just 18 days unaccounted for. As of now, the dataset still excludes WhatsApp messages, which has an impact on a few select parts of the dataset at times when that was our primary means of text communication (marked on the visualization below), but has relatively little impact overall.
The data set contains 294,065 messages total, exchanged over 6+ years. It averages out to 130.9 messages per day (including days on which 0 messages were sent, but excluding the dates for which there is no data). As per Voyant, the most frequent words in the corpus are just (23429); i’m (19488); ok (17799); like (13988); yeah (13845). The dataset contains 2,047,070 total words and 35,407 unique words. That gives it a stunningly low vocabulary density of 0.017, or 1.7%.
Counting only days where messages were exchanged, the minimum number of messages exchanged is 1 — this happened on 29 days. The maximum number of messages exchange in one day is 832. (For some qualitative context to go with that high number: it was not a remarkable day, just one with a lot of texting. The majority of those 832 messages were sent from iMessage on a computer, not a phone, which makes such a volume of messages more comprehensible, thumb-wise. I reread the whole conversation, and there were two points of interest that day that prompted lots of messages: an enormous, impending early-summer storm and ensuing conversation about the NOAA radar and where to buy umbrellas, and some last-minute scrambling to find an Airbnb that would sleep 8 people for less than $40 a night.)
I was curious about message counts per day — while it’s definitely more data viz than text analysis, I charted messages per day anyway, and added some qualitative notes to explain a few patterns I noticed.

Chopped in half so that the notes are readable:

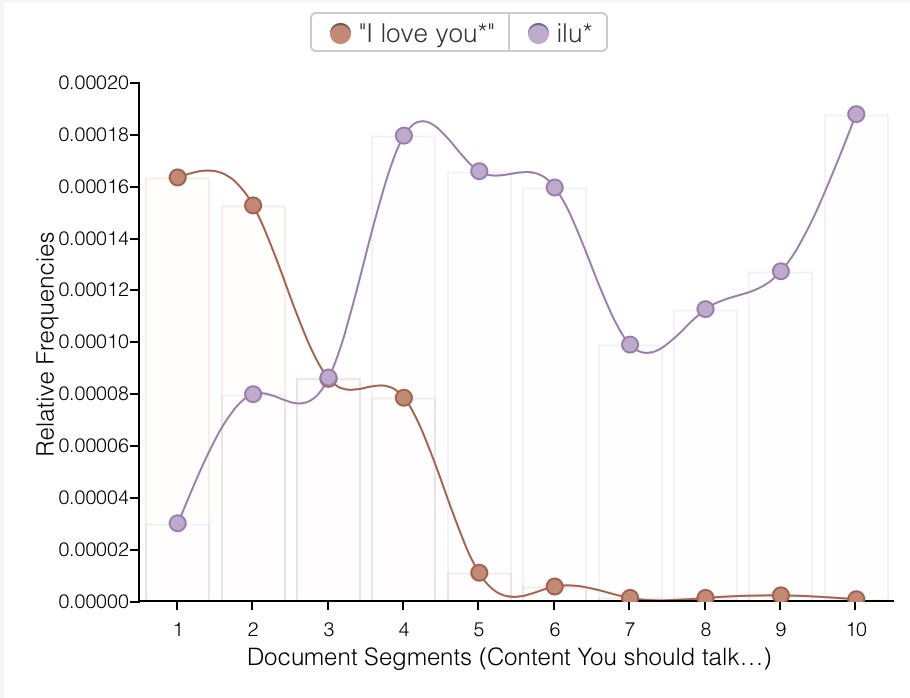
Despite my mild horror at the mundanity and ad nauseam repetition of “ok” and “lol,” I had fun playing around with different words in Voyant. I know from personal experience, and can now show with graphs, that we have become lazier texters: note the sudden replacement of “I love you” with “ilu” and the the rise of “lol,” often as a convenient, general shorthand for “I acknowledge the image or anecdote you just shared with me.”

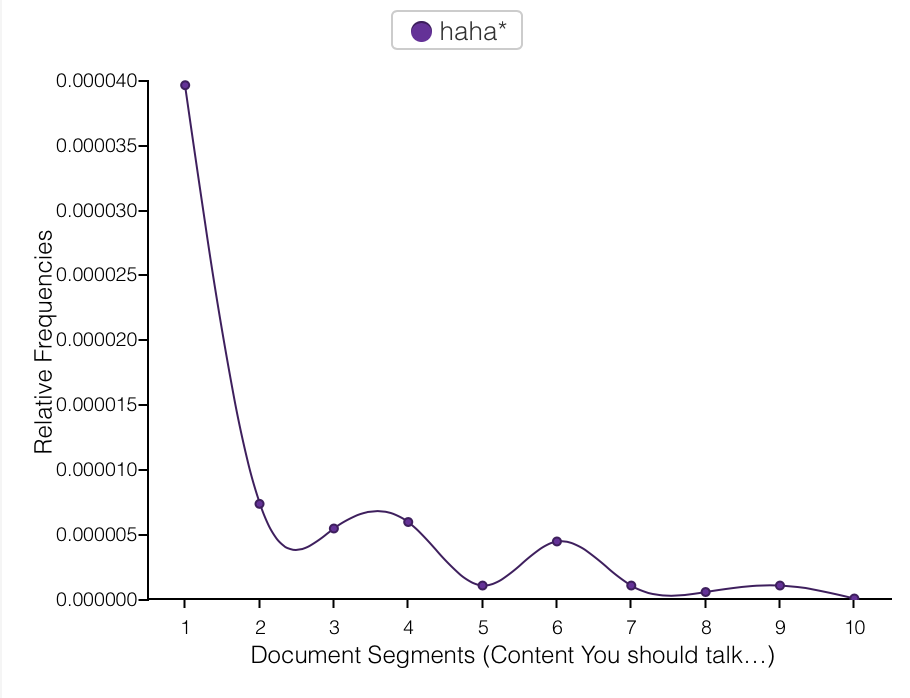
On the subject of “lol,” we have the lol/haha divide. Note the inverse relationship below: as “lol” usage increases, “haha” use decreases. (The two are best visualized on separate charts given that “lol” occurs more than 10 times as frequently as “haha” does.) I use “haha” when I don’t know people very well, for fear that they may feel, as I do, that people who say “lol” a lot are idiots. (“Lol” is the seventh most frequently used word in this corpus.) Once I have established if the person I’m texting also feels this way, i.e. if they use “lol,” I begin to use it or not use it accordingly. Despite this irrational and self-damning prejudice I have against “lol,” I use it all the time and find it to be one of the most helpful methods of connoting tone in text messages — much more so than “haha”, which may explain my preference for “lol”. “You are so late” and “You are so late lol” are completely different messages. But I’m getting away from the point… see “lol” and “haha” graphed below.

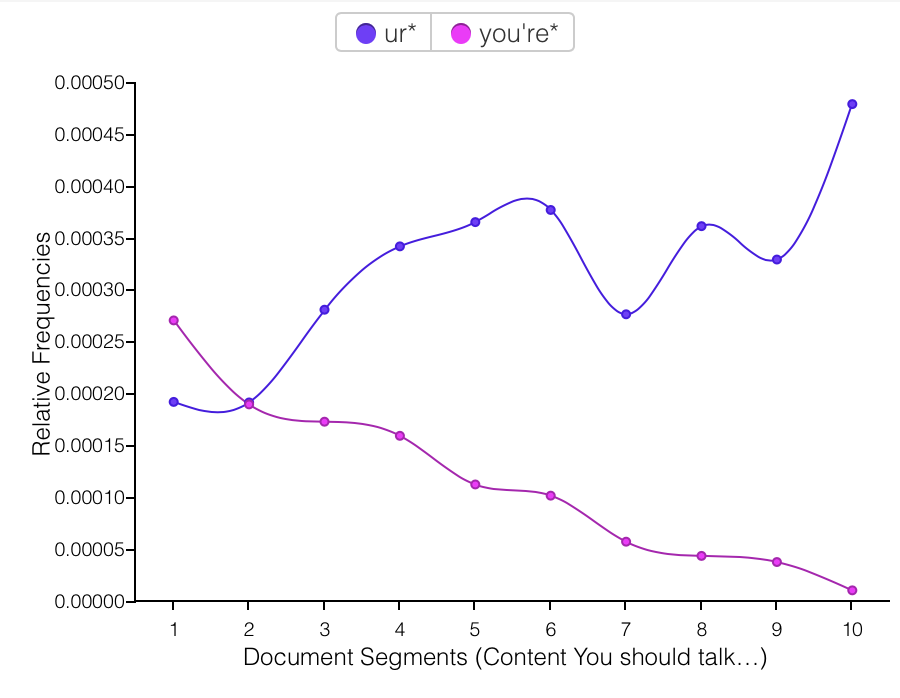
The replacement of “you” with “u,” however, I do not interpret as laziness, or as personal preference winning out, but as a form of ironical love language. At some point over the narrative span of this corpus, using “u” was introduced as a joke, because both of us were irked by people texting w/o putting any effort in2 their txts bc it makes it rly hard 2 read n doesnt even save u any time 2 write this way? And then it turned out it maybe does save a tiny bit of time to write “u” instead of “you,” and more importantly “u” began to mean something different in the context of our conversations. Every “u” was not just a shortcut or joke, but had, with humorous origins, entered our shared vocabulary as a now-legitimate convention of our communal language. Language formation in progress! “Ur” for “you’re” follows the same pattern.

With more time, I would like to evaluate language from each author in this corpus. It is co-written (52% from me, 48% to me) and each word is directly traceable back to one author. Do we write the same? Differently? Adopt the same conventions over time? My guess is that our language use converges over time, but I didn’t have time to answer that question for this project.
I began this text analysis feeling pretty disappointed with the data. But through the process of assigning meaning to some of the patterns I noticed, I have come to appreciate the data more. I also admit to myself that once I had the thought that text messaging– writing tiny updates about ourselves to others– is a modern epistolary form, I perhaps subconsciously expected it to follow in the footsteps of Evelina… which is an obviously ridiculous comparison to draw. Or for it to evoke to some extent the letters written between my grandparents and great-grandparents, which is a slightly less ridiculous expectation but one that was still by no means lived up to. Composing a letter is a world away from composing a text message. Editing vs. impulse. Text messages are “big data” in a way that letters will never be, regardless of the volume of a corpus.
Would it be fascinating or incredibly tedious to read through your grandparents’ text conversations? Probably a bit of both, satisfying in some ways and completely insufficient in others. It’s not a question that we can answer now, but let’s check again in fifty years.
Eva, this is amazing! Also in a 6 year relationship that lives on through text and iMessage from the very first in my iPhone, this is one of the niftiest applications I’ve seen. I must know the software you used to get all your texts!
Well done – I loved reading about your project!
I agree with Marie. This is amazing. I especially appreciate your insight about the word cloud “drivel” and how the visualization alone doesn’t get to the core of your memory or depth of the relationship.
Thank you both! Marie, the program I used is called iExplorer — it’s proprietary but not super expensive (I think I paid $40 and was able to transfer the application from my last computer without re-purchasing a license). I know there are other similar programs available as well. Happy to give more details/show you what it looks like in action if you want.
Hi Eva! I’ve been glancing back at some of the text analysis projects for our class, and I wanted to first echo what Marie and Rena said above. When I first read through your project in late November, I thought it was pretty astonishing how much your dataset seemed to tell a story about the course of your relationship these past six years. The non-platonic social etiquette of text messaging has always struck me as understatedly complex, not only reflecting but also at times altering the scope of certain relationships. Your approach here seems to shed light on that unspoken complexity in a really cool and approachable way, so props for that!