

When I began this text analysis praxis, I thought I might try out one of the flashier tools in the list, maybe Voyant, Google N-Gram, or MALLET (which I did end up playing around a bit with, but ran out of time trying to find all the texts I wanted to build a decent sized corpus). I had hoped to end up with some interesting findings or at least some impressive images to share with you on this blog post! What I did decide on was the JSTOR Text Analyzer, definitely the least sexy option in the list, but for me, probably the most useful tool for my daily work as a librarian.
I will be completely honest and say that I am not a fan of paywalls and the companies that build them, that being said, many academic institutions subscribe to JSTOR and as an academic librarian I need to understand what are the tools that can best help library patrons. Using the Text Analyzer tool is simple, nothing to download, no code to write, you just upload a document with text on it, (they say even if it is just a picture of text) and the tool will analyze it and find key topics and terms, then you get to prioritize these terms, change the weight given to them in the search and use them to find related JSTOR content.
This all seems simple enough, they say they support a whole slew of file types (csv, doc, docx, gif, htm, html, jpg, jpeg, json, pdf, png, pptx, rtf, tif (tiff), txt, xlsx) and fifteen (!) languages including: English, Arabic, (simplified) Chinese, Dutch, French, German, Hebrew, Italian, Japanese, Korean, Polish, Portuguese, Russian, Spanish and Turkish. And as a bonus, they will even help you find English-language content if your uploaded content is in a non-English language. This all sounded too good to be true, so I thought I would go real-world and drop in a bunch of real syllabi (see course list below) from professors I have helped this semester and see how the JSTOR Text Analyzer would score.
Courses
- Philosophy of Law (Department of Social Science)
- Building Technology III (Department of Architectural Technology)
- Information Design (Department of Communication Design)
- Sustainable Tourism (Department of Hospitality Management)
- Electricity for Live Entertainment (Department of Entertainment Technology)
- Hospitality Marketing (Department of Hospitality Management)
The Process
The first course I tried was Philosophy of Law. I used the “Drag and Drop” feature to upload a pdf of the course syllabus. Once the file is “dropped” into the search box, the JSTOR Text Analyzer takes over and produces results in seconds. This is what my first search produced. The results were somewhat relevant to the course and not too bad for a first try. At this point I decided to add a few terms from the syllabus and change the weight that those terms are given in the search.
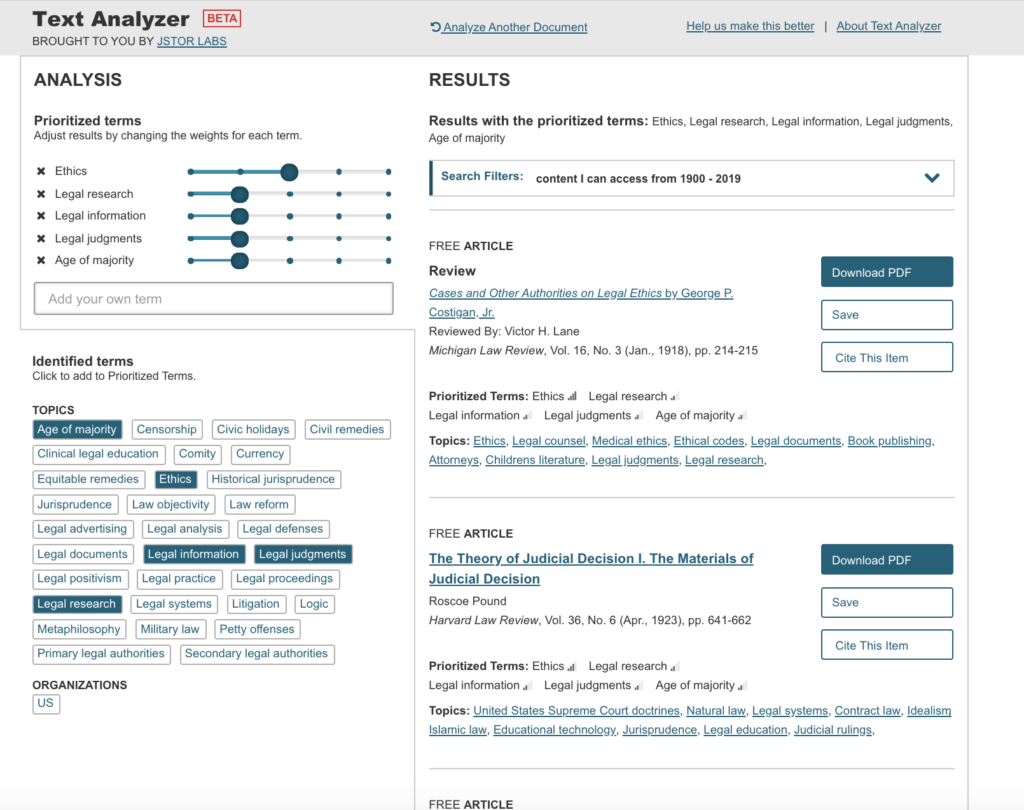
Here are the results of my second, modified search.

Next I uploaded a csv file of a syllabus for Building Technology III. The Text Analyzer had no problem with the change in file format. The search results for this course were a bit strange though, with an article about the Navy’s roles and responsibilities in submarine design being the first in my results list. I am not sure where the JSTOR algorithm inferred the military and submarine from as there was nothing in the syllabus that made reference to these subjects. Oh the mysteries of the “black box algorithm”.

I then did the same addition and deletion of terms and adjusted term weights as I did for the previous course, Philosophy of Law. The new search results were much closer to the actual course content, though I did expect to see more about steel.

For my next experiment, I chose to take a screenshot of the syllabus for Information Design and import the png image file into the Text Analyzer. Unfortunately, even though they say they support png files, I received the following when I uploaded mine.
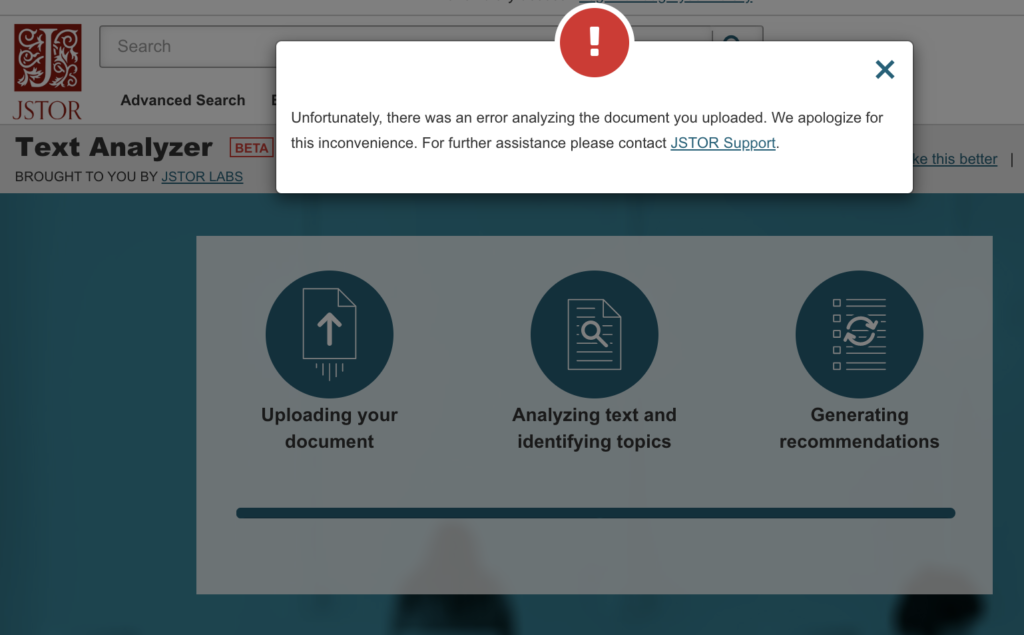
File types supported
https://www.jstor.org/analyze/about
You can upload or point to many kinds of text documents, including: csv, doc, docx, gif, htm, html, jpg, jpeg, json, pdf, png, pptx, rtf, tif (tiff), txt, xlsx. If the file type you’re using isn’t in this list, just cut and paste any amount of text into the search form to analyze it.
I then went back to uploading pdfs and did not have any further problems with importing the syllabus for Information Design. The initial search results were not bad and actually got worse when I modified the terms to reflect what was in the syllabus.
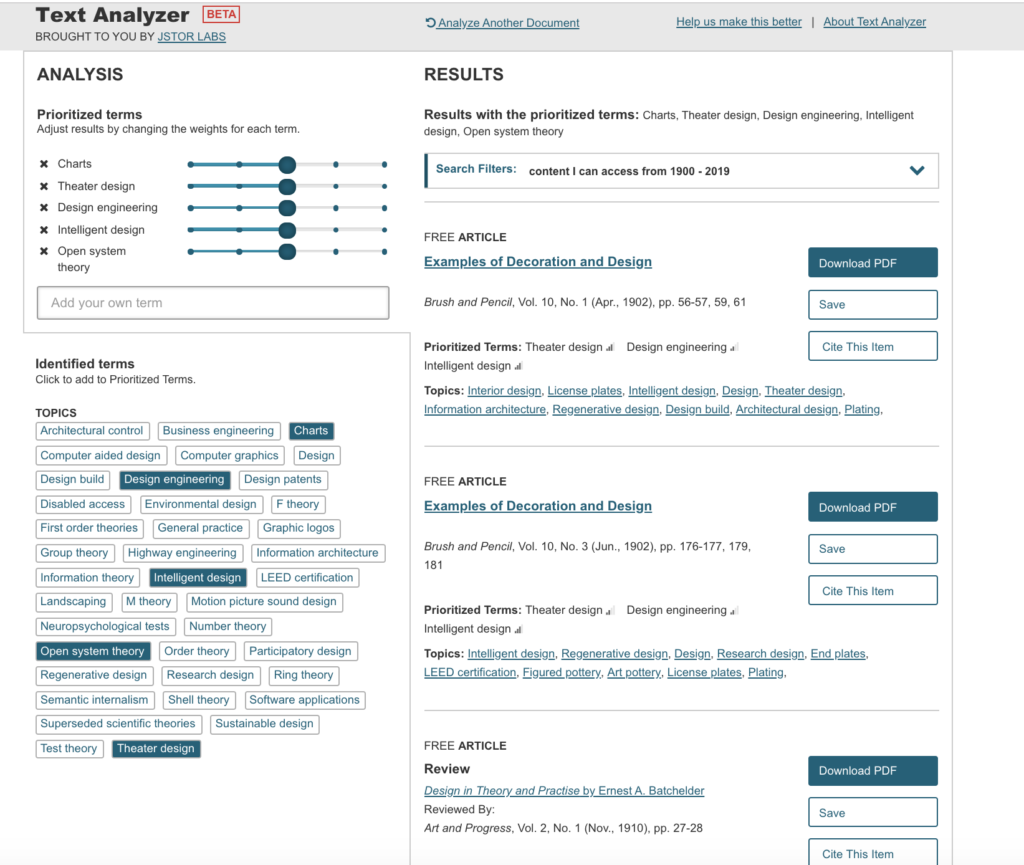
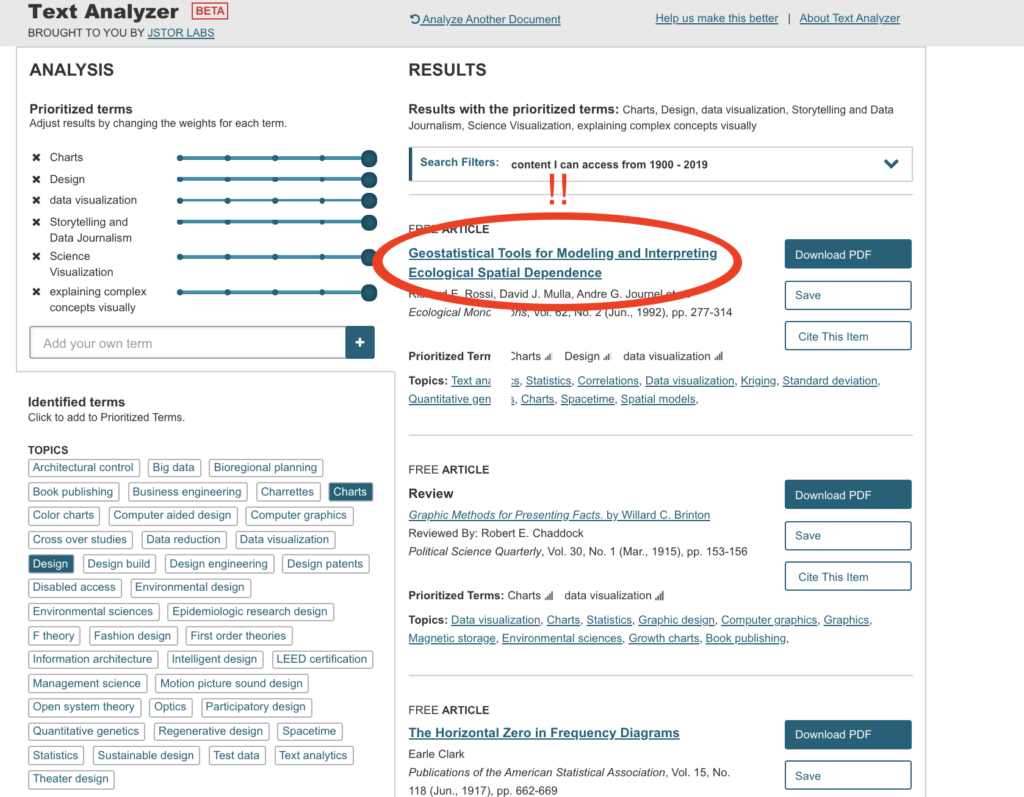
The syllabus for Electricity for Live Entertainment uploaded with no problems and the results were interesting and made reference to electricity but not entertainment.
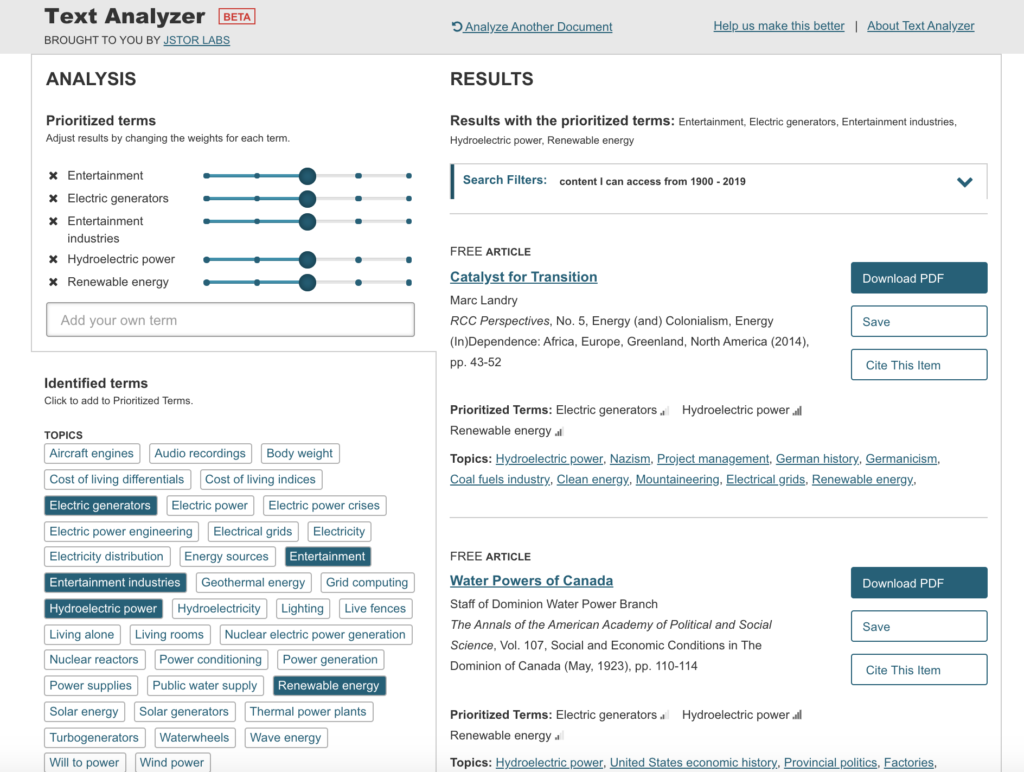
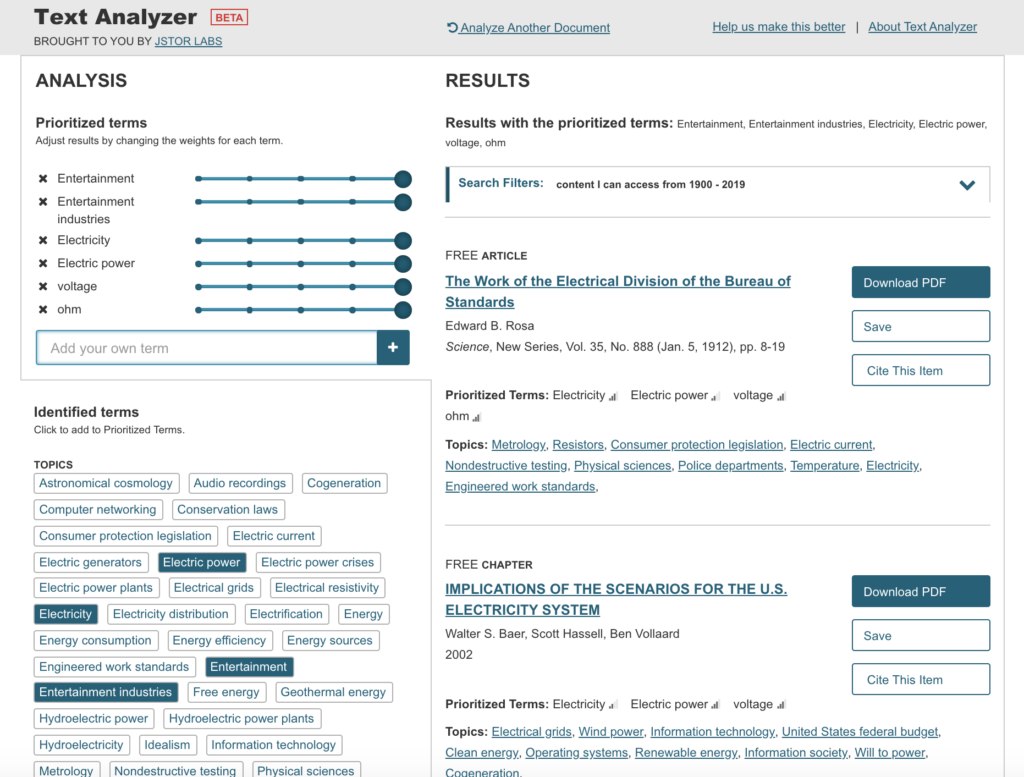
The modified results were far more relevant to the course content.
I then moved on the Sustainable Tourism. Things went really weird when I tried to upload a url for a course website that contained the syllabus (all these are Open Educational Resource – OER – courses) and the Text Analyzer picked up some crazy stuff, maybe from the metadata of the website itself??

I then uploaded the syllabus directly, as a pdf and received pretty accurate search results.
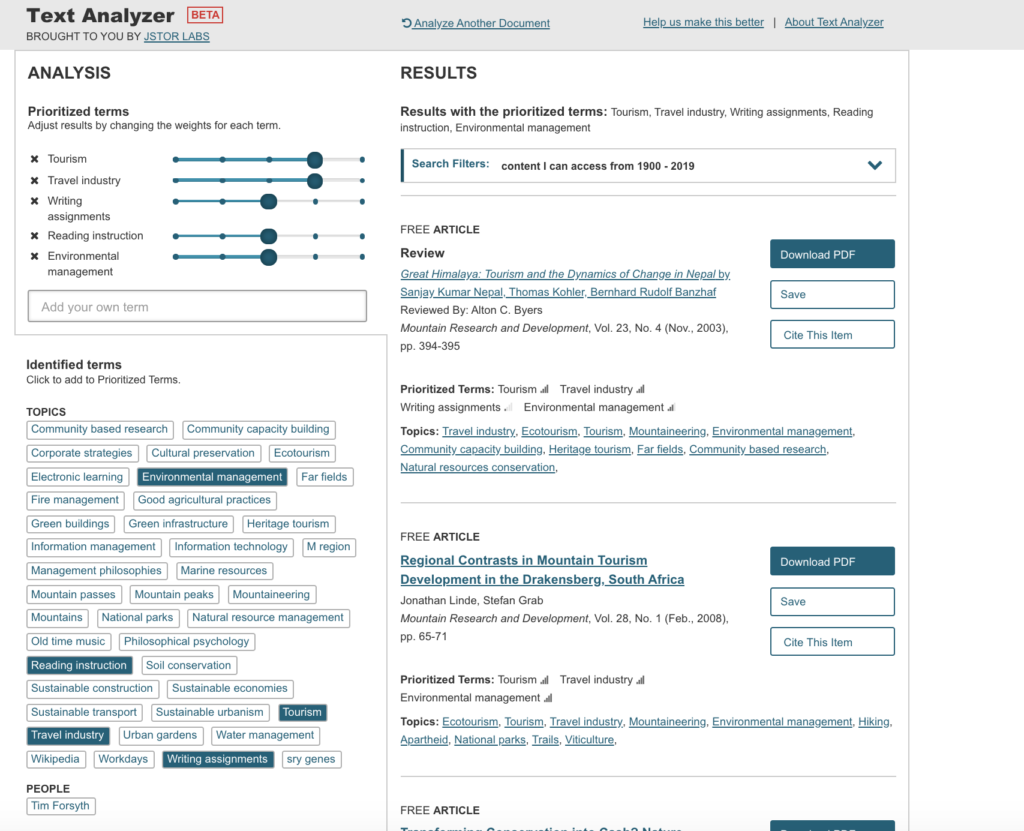
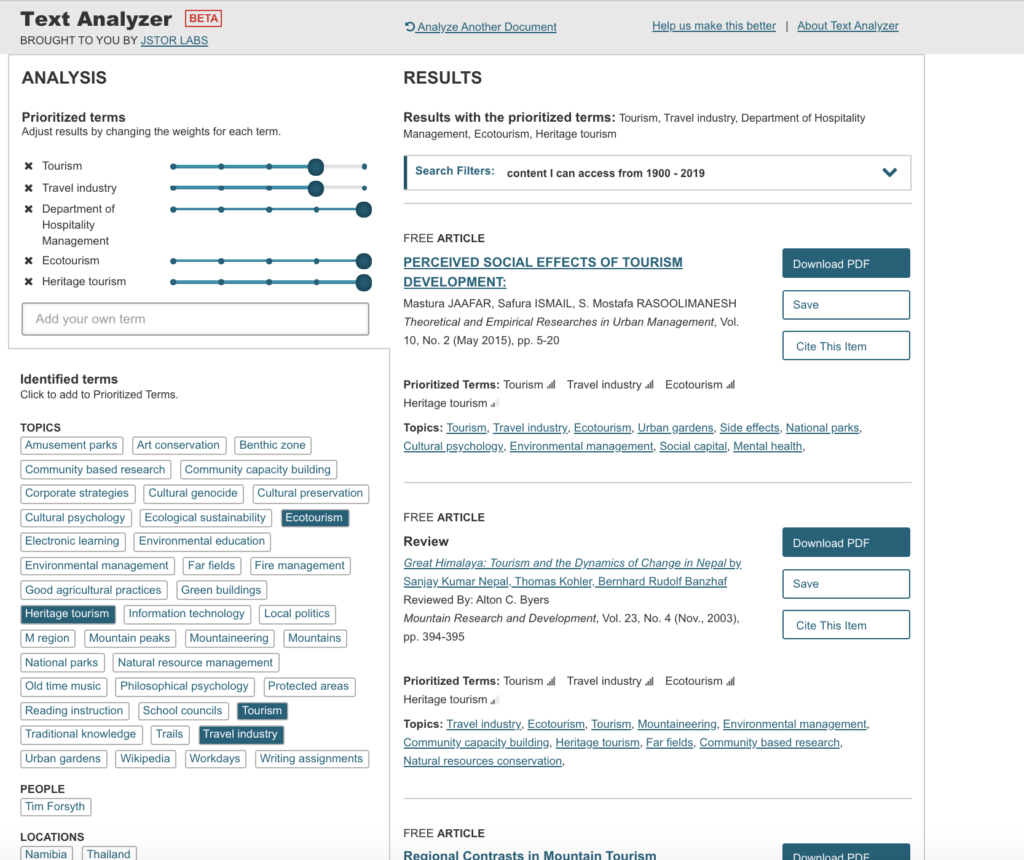
Modified results for Sustainable Tourism were even better.
The search results for Hospitality Marketing, upload by pdf, were completely off, not even close.
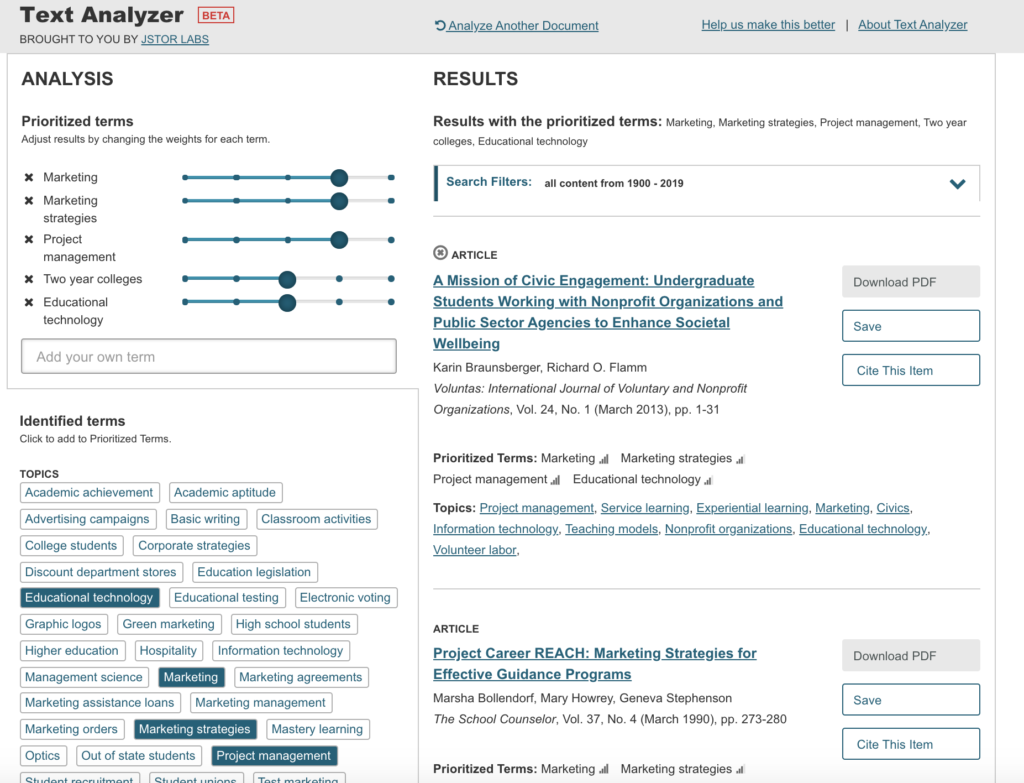
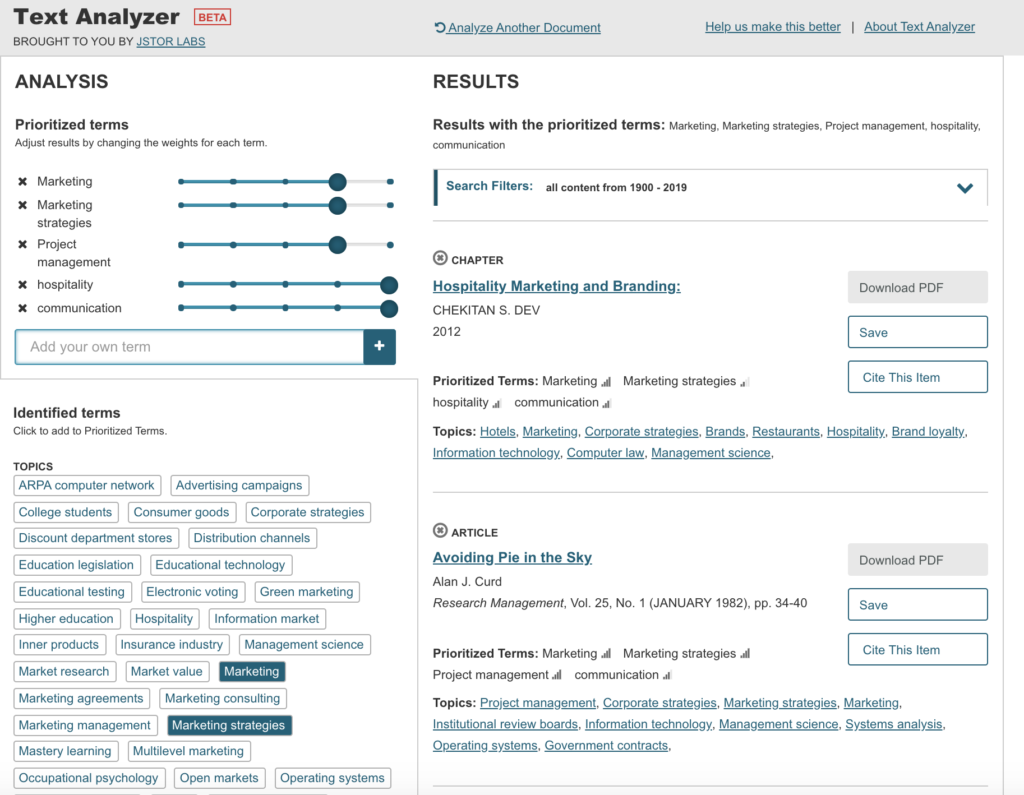
Modified terms and weights gave me much better and more accurate results.
My Thoughts
In the end, the JSTOR Text Analyzer is not a bad tool for finding content based on textual analysis of an imported file. Upload is simple and the results, while mixed, are generally in the ballpark. Adjustment of terms and weight is almost alway necessary, but not difficult to do. I probably use and recommend this tool. I did not log in and instead used the “open” version of content, but if you have access to JSTOR content through your institution, you would probably get different and maybe even better results.
And because no text analysis project is complete without a world cloud, here is one I made using text from all the syllabi I uploaded into the JSTOR Text Analyzer.


This entry is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International license.