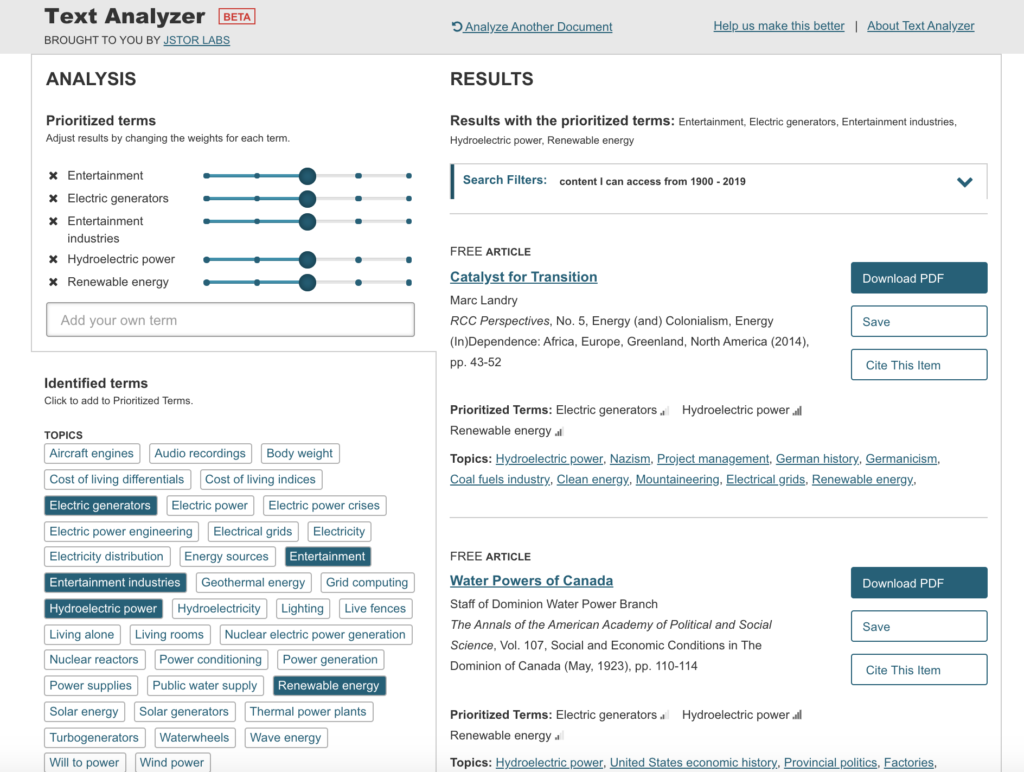
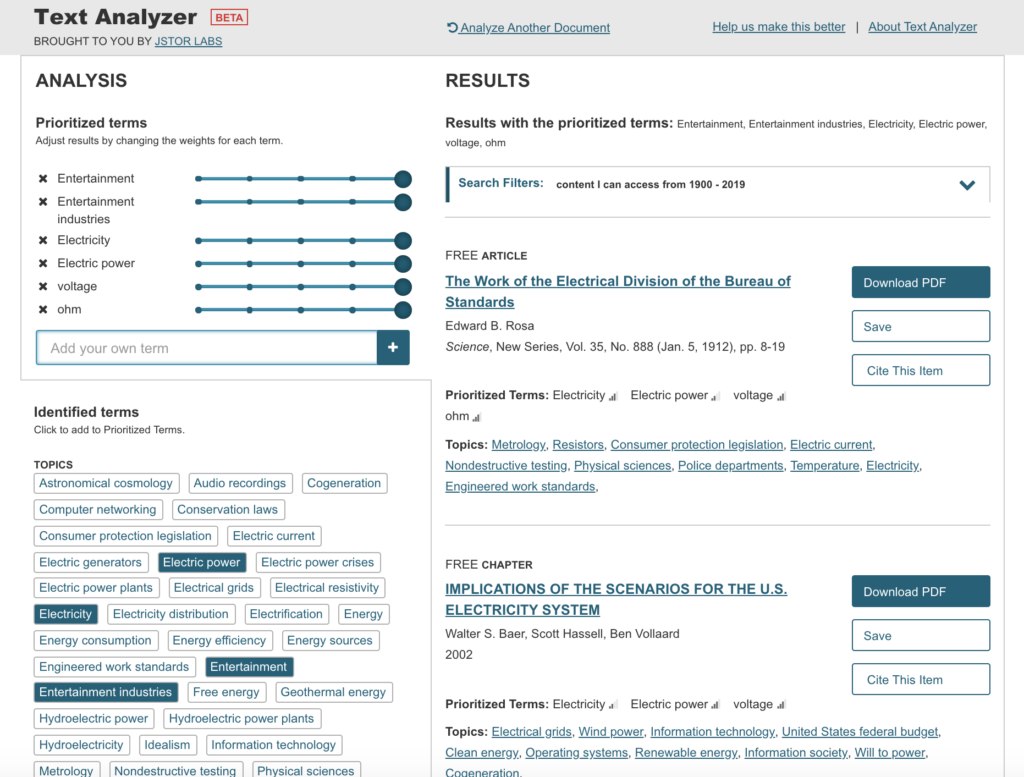
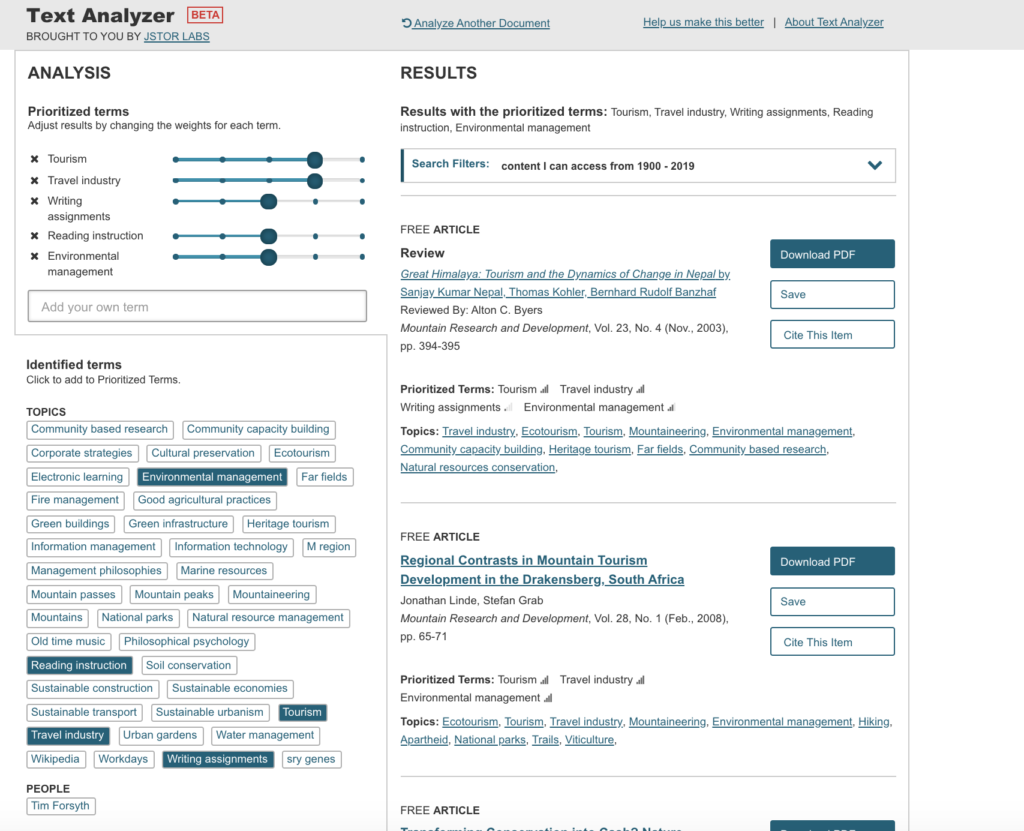
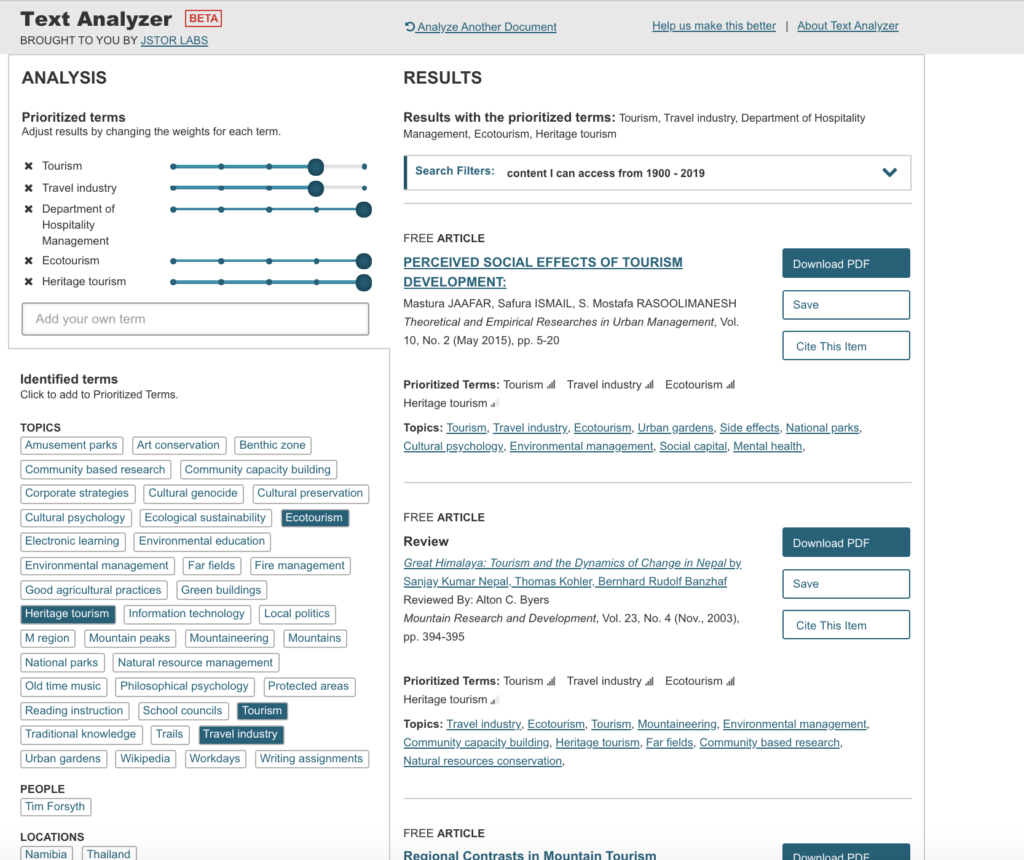
Can we use geospatial tools to explore the human condition and tragedy? The Triangle Shirtwaist Factory Fire Revisited: A Geospatial Exploration of Tragedy aims to do just that, by introducing the viewer to a historical event, the Triangle Shirtwaist Factory Fire of 1911, through the use of interactive geospatial technology. The project presents the viewer with the home addresses of all 146 victims of the Triangle Shirtwaist Factory Fire, their burial places, and major geographic points related to the fire, identified by points on a map. The project uncovers siloed documents and information, bringing them together in a singular context for a more intimate understanding of an event and the primary sources that document it. This project intends to create a single access point via a digital portal for interaction by the user. Creating this portal offers the user the freedom to interact with the information contained within the map at their own pace, and explore the information that most appeals to the user. The Triangle Shirtwaist Factory Fire Revisited project is built on a dataset complied from archive photographs, letters, journalism, artwork, home, work, and gravesite addresses all relating to the fire victims.

Modeling historic events with geospatial data has been shown to be an impactful way to explore history in digital humanities projects such as Torn Apart / Separados http://xpmethod.plaintext.in/torn-apart/volume/1/, Slave Revolt in Jamaica, 1760-1761: A Cartographic Narrative http://revolt.axismaps.com/, and American Panorama: An Atlas of United States History http://dsl.richmond.edu/panorama/.
The Triangle Shirtwaist Factory Fire Revisited continues the expansion of geospatial exploration in the digital humanities by presenting the user with the ability to explore the horrific event of the Triangle Shirtwaist Factory Fire through the lives of the victims. By creating an interface that will allow the user to explore an event through their own direction, the user can take ownership over learning about a historical event through their own research. This project encourages the user to examine underrepresented histories and also provides a way for them to engage with primary sources and digital tools. This project is committed to grounding geospatial concepts in the humanities for thinking critically about the relationships between events, people, movements, laws and regulations, and journalism.
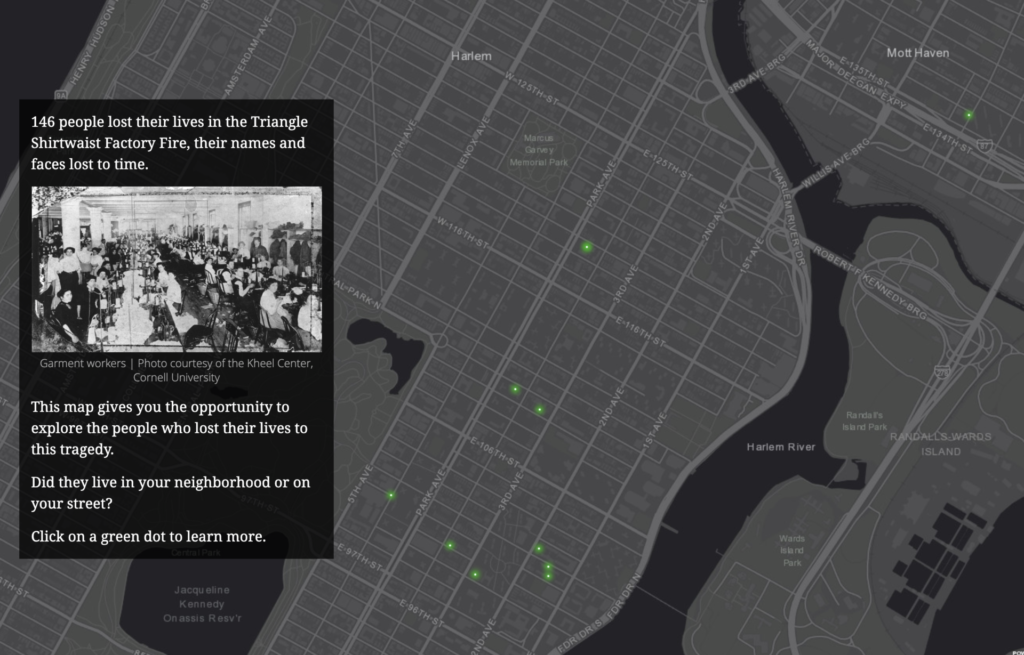
The Triangle Shirtwaist Factory Fire Revisited project will be built in three phases: 1) research and data collection, 2) prototype design and review 3) digital portal creation, followed by user testing. Phase 1) research and data collection— Information about the 146 victims was gathered from David Von Drehle’s book Triangle: The Fire that Changed America, the Cornell University Kheel Center website Remembering the Triangle Shirtwaist Factory Fire of 1911 (https://trianglefire.ilr.cornell.edu/) which includes Michael Hirsch’s research on the six previously unidentified victims and also from the Find A Grave website (https://www.findagrave.com/). Additionally, the information and letters included in Anthony Giacchino’s 2011 Triangle Fire Letter Project (http://open-archive.rememberthetrianglefire.org/triangle-fire-letter-project/) was included to add another dimension to the information landscape of these 146 victims. This information was compiled and reviewed for accuracy, then a dataset was built. Relevant primary and secondary sources were then identified and incorporated into the dataset. Addresses were geocoded (latitude and longitude locations added to the addresses). Phase one is complete. Phase 2) prototype design and review — The dataset built in phase one was then used to create several digital geospatial prototypes (see Appendix). Further review will need to be done to complete Phase 2 and move forward with the project. Phase 3) digital portal development, creation & user testing— For this phase, the project team will continue to review prototypes created in phase 2, determine the mapping software to be used, features and information to be included, and then begin building the final map. Once the digital map and interactive portal is complete, user testing will be begin and adjustments will be made based on comments and recommendations made by the user testing group, pending final approval by the project team.
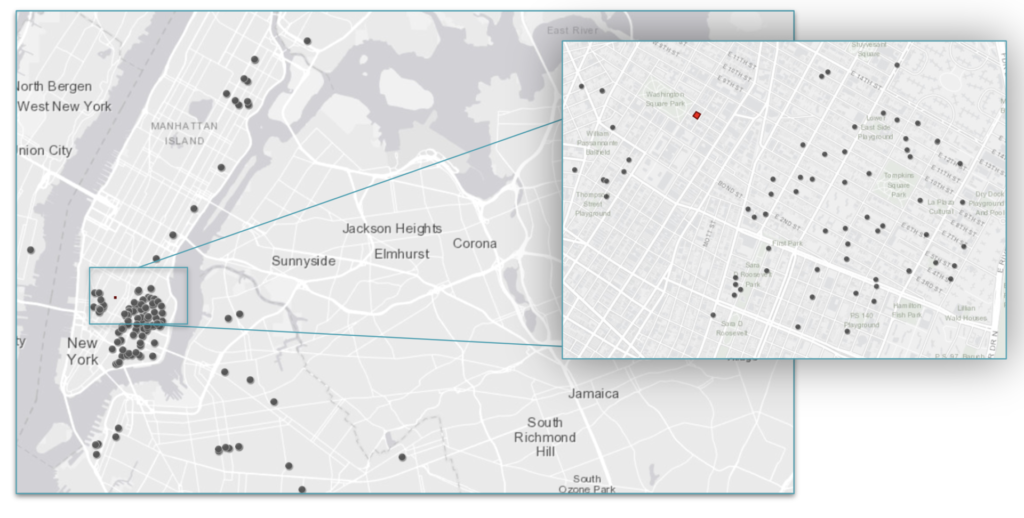
The final product, a digital, interactive geospatial (map) interface documenting the Triangle Shirtwaist Factory Fire of 1911, that will allow the user to explore this historical event, and those connected to it, at their own direction will be published openly on the internet under a Creative Commons license that would allow others to freely use the code and dataset to build their own geospatial project. Once the project is publicly available, a Github repository for the tools used, data gathered, and dataset created will be established and populated, allowing further research to be done using the tools and data collected by the project team. In addition, a detailed account of the building of the project, including lessons learned, will be added to the Github repository with the hope of providing future researchers a formula for success and review of best practices for a digital mapping project. We will also use social media, blog posts on digital humanities and geospatial websites, conference talks and presentations with relevant academic associations to further publicize the project.