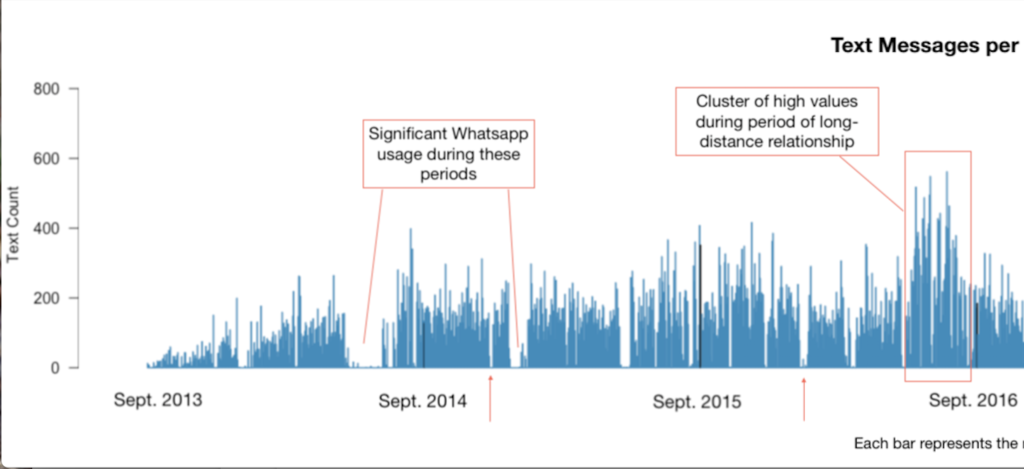
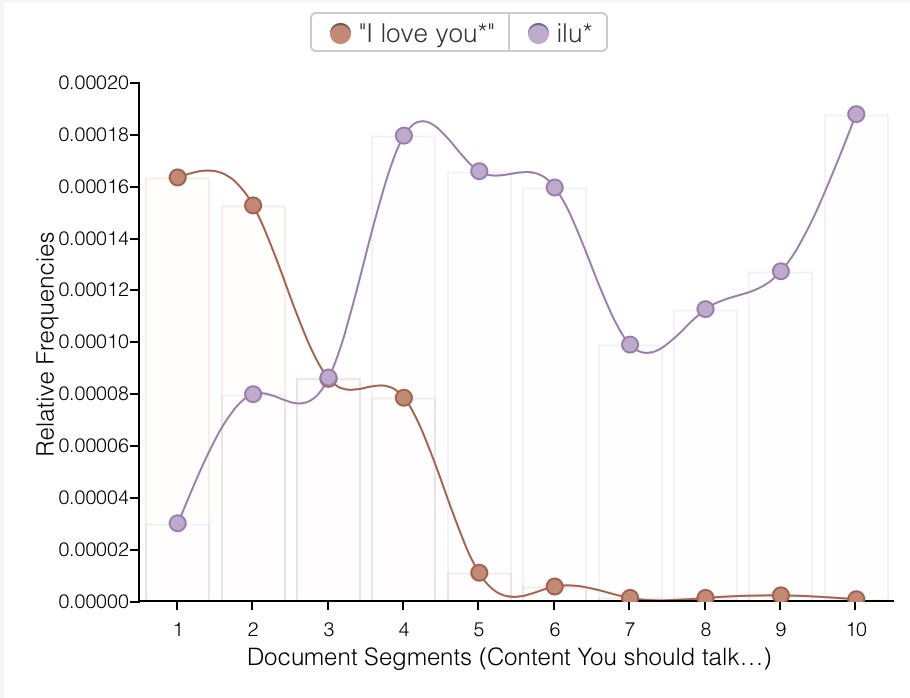
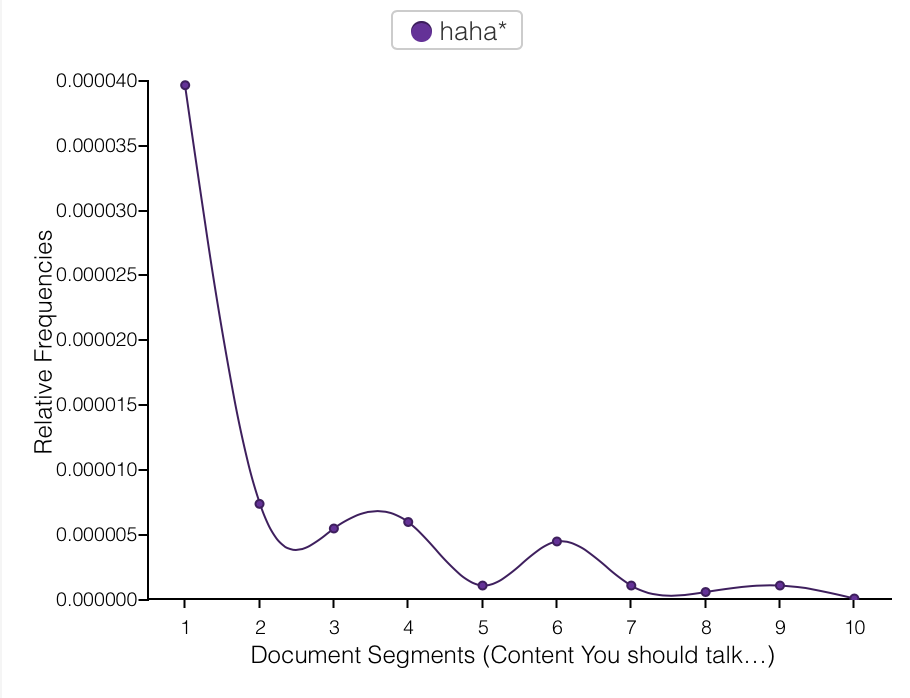
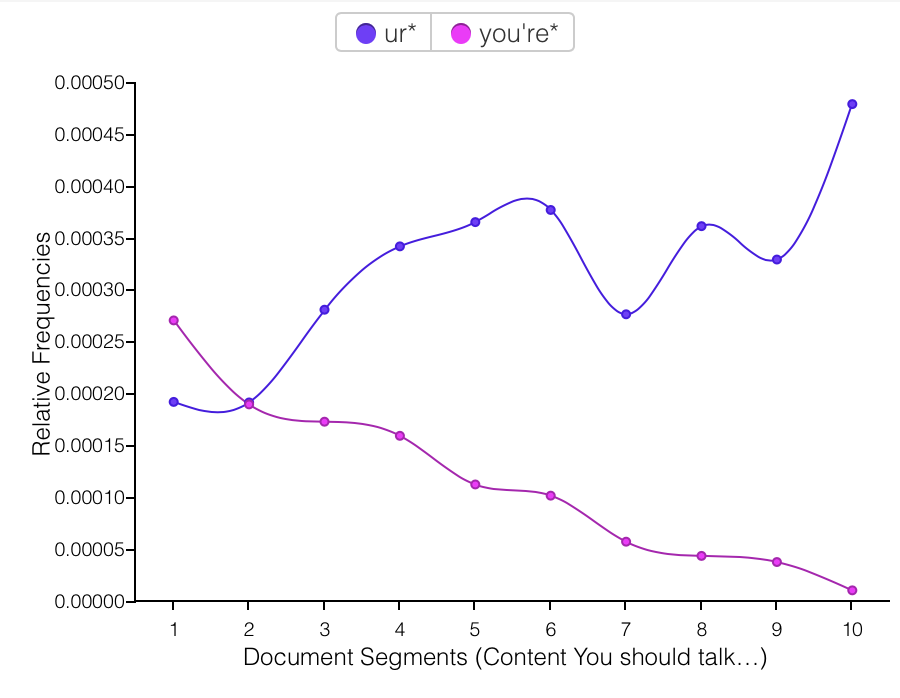
This was one of the hardest assignments I’ve ever done… I feel like I’ve spent hours and hours getting closer to the end, and mostly didn’t feel any closer. I showed it to someone on Sunday and she said, “wow, looks like you’re almost done!” And I said, “Yeah!” And then I put another 20+ hours of work into it and still feel like I could do 10 more if I had the time. But I found a stopping point that feels adequate enough, so I’ve stopped for now. I don’t want to post it online, but if anyone wants to check it out, I’m happy to email it or post it in the forum.
Here are some reflections about my choices, since I don’t get to defend them in the syllabus itself.
(And first of all, this syllabus has much more detail about in-class assignments/activities than other syllabi I saw, but when I started taking them out to make it look like a real syllabus, I felt the pedagogical loss too keenly. Can’t kill my darlings this time.)
I chose to include some feminist texts without having a “feminism unit” because I’m only now realizing how useful and universally applicable I find feminist theory to be. (@Lisa Rhody, thank you!) I did not take a Gender & Women’s Studies class as an undergraduate, and as such I got pretty much zero exposure to academic articles or materials that were labeled as explicitly feminist, despite engaging with recognizably feminist ideas and many feminist scholars. I didn’t know that some of the core ideas of feminism are about standpoint, bias, and objectivity, but it’s clear to me that these ideas are important for any researcher or critical thinker. I was hesitant at first to include the Koen Leurs piece, for example, but talked myself into it by imagining how helpful it might have been for me as an undergraduate to read feminist methods in action, and see how they can be applied to any question. It would have upset my misguided notion that “learning feminist theory” could only mean taking GWS 101.
I tried to include art and multimedia, and that too was difficult. It feels just right to me to include Yoko Ono’s Grapefruit in a discussion of giving instructions/writing algorithms. It’s easy for me to imagine it as an extension of Rafa’s physical explanation of for loops, using chairs, at the Python workshop in October, and I think it would make for a similarly memorable and intuitive understanding of how computers work through problems and how algorithms are structured. I’m a little less clear on the value of including thewrong.com, an online biennial that is more or less unstructured and aims to disrupt the deeply entrenched hierarchies of the art fair world. In theory, I think it fits well in a discussion of online values and shaking up entrenched value norms. In practice, it may be too much of a leap for students, or its context may be too obscure for those with minimal knowledge of the art world.
And that leads me to the next difficulty. I struggled to balance making a course that could answer the very basic questions and not scare off students for whom “algorithms” are a complete mystery. But I also want to challenge students, and not underestimate their abilities. My guess is that if anything, this class can and should delve deeper, with more theory and more academic articles to build a more robust epistemological base for thinking about the internet. But I also wanted to keep the focus on the everyday, so although including as many media sources as I did may feel less challenging to the students, I hope that it would pay off in terms of relevance and applicability.
I included free-writing for a couple reasons. Firstly, I appreciated it in our class as an opportunity of time and space to think about the readings without having to share with the whole class (although let’s be real, I clearly don’t have a problem sharing with the whole class…). Additionally, early on in creating my syllabus, I found Kris Macomber and Sarah Nell Rusche’s “Using Students’ Racial Memories to Teach About Racial Inequality” to be an incredibly accessible and helpful resource in imagining a classroom environment in which students were having meaningful conversations about race and the internet. Free-writing, as Macomber and Rusche write, gives an opportunity for all students to consider their own experiences, and then to share/connect those experiences to course concepts with whatever degree of structure and guidance seems most beneficial.
Some last grab bag things: I included an open day, and put it in the middle of the semester so that student input could potentially shape the second half of the course beyond that day. I chose to use QGIS because it’s free and open source, and it works on Macs or PCs. I found it difficult to get scholarly sources on the history of digital advertising— I’d fix this up in the next draft.
“Priming” became a really important consideration for me — on almost every single day, I found myself wondering if I should switch the order of the lecture and the readings. This was usually a response I could trace to my own lack of confidence in my imaginary students, and therefore one I dealt with by reminding myself that I have countless times learned or thought about something for the first time in a reading and then had it further explained and contextualized in a lecture or class discussion. I cannot control what my students take away from the class anyway (nor should I), so as long as I avoid leaving large contextual gaps or assigning anything that is too jargon-heavy to make sense of, it is probably best to let students sit with the material on their own first and begin class by asking what they think of it.
And finally, a note on confronting my accumulated academic privileges. I tried to take up the challenge to envision this course as part of the CUNY system, and the best spot I could find for it was the American Studies Department at City College. (I’d be curious to know if there’s a better place, though!). Figuring this out helped me to reflect critically on a few things about my own undergraduate experience.
I knew in the abstract that I was privileged to be at Bowdoin College while I was there. But designing this course for a CUNY school helped me to realize a couple of specific privileges inherent to taking an Interdisciplinary Studies Course called Data Driven Societies at Bowdoin College (an amazing course that inspired my pursuit of DH). Privilege went beyond the thirty brand new MacBook Pro computers connected to thirty brand new chargers in a neat little locked cart that were stored at the back of our classroom for lab periods. It extended to the fact that Bowdoin College even had an Interdisciplinary Studies department. How much less career-skill-oriented can you get than an interdisciplinary department at a liberal arts college? And my own privilege extended to the fact that my parents, who paid for my education, didn’t blink an eyelash when I told them that I would be taking the class.
Part of recognizing my own privilege is recognizing that I didn’t ask “where does this syllabus fit into an existing scheme of funding” until the very end. Which is why at 11:30pm on Tuesday and I was frantically looking to figure out how I’d get laptops, whether City College has a computer lab I could use for the lab sections, and trying to figure out how I could change my syllabus for a more minimal-computing approach if a computer lab wasn’t possible. But it was a bit late to change the syllabus that much, and in fact I believe there could be computer labs available for a class like this one at City College!
I may have failed at making a CUNY-ready syllabus. It’s easier for me to imagine the course being successful at a small private college, which I guess makes sense because I’m much more familiar with the resources available, the academic culture, the student body, and the classroom dynamics in that setting. Luckily it’s a first draft, though, and since I’m submitting it into the CUNY world, there’s more than a little hope for its improvement in this regard and others!
Finally, I’d like to acknowledge Professors Jack Gieseking and Kristen Mapes, whose pedagogical approaches and syllabi were invaluable to me in attempting this project.