
With our class having recently discussed our collective frustration and ignorance toward the terms and conditions of “Big Tech” companies, I felt it worthwhile to take a look at the privacy policies of major technology corporations — and some of their subsidiary digital platforms — in not only the United States, but also China. Part of my reasoning behind this international perspective on the tech sector draws from an interest in probing at some of the similar and disparate ways in which major American and Chinese tech companies articulate their terms and conditions regarding the management of user privacy and personal data. At the onset of my project, I didn’t necessarily have a concrete grasp on what sort of trends I expected to find, but I also felt as though this uncertainty might lend itself to a few hidden insights given that I to some extent let the data do the talking. Situating myself in the playful spirit of to “the hermeneutic of screwing around,” vis-a-vis Stephen Ramsay, I wanted to poke around inside of these deconstructed corporate texts, to unravel their legalese and consolidate it into a dataset, picking and prodding at trends in their diction, syntax, and structure. Meanwhile, I thought it important to keep an eye out for subject matter that might have otherwise gone unacknowledged by 91% of users when checking the proverbial box: the vast majority of us consumers who at the mere sight of these ghastly documents choose to throw our arms in the air before abruptly agreeing to the terms and conditions.
In the spirit of normalizing failure and learning from past mistakes, I’d like to note that my ambition exceeded my grasp when first gathering text corpora for this project, if only because I started by compiling data on individual privacy policies and service agreements from Amazon, Facebook, and Twitter, as well as Alibaba, Sina Weibo, and WeChat. This entailed that I gather twelve total files for text analysis in Python. I intended to analyze each file for three specific linguistic measurements — term frequency, bigram frequency, trigram frequency — which, as far as Excel columns go, meant multiplying twelve times six due to the fact that each corpus requires three columns for its key (e.g. “privacy, notice”) and three columns for its value (e.g. “9”) Suddenly the number of columns of data in my spreadsheet ballooned to 72, which of course is too much data for one person to qualitatively parse in a limit time span. Needless to say, I had some reflecting to do.
In writing code to preprocess these text files, I decided to clean house on punctuation, uppercase characters, as well as integers. These alterations are not without ambivalence. Indeed, I think there are salient insights hidden among the use of numbers across these corpora. For one, these documents are written in a legal register that so happens to self-reference numbered sections with its own set of terms and conditions, disclosed earlier or later in a given document. While robust on a legal level, this technique doesn’t exactly enhance readability despite the fact that these documents are explicitly meant for consumers who must in turn agree with its obtuse parameters. In any case, these documents don’t self-reference themselves via numbered sections so often that it becomes a problem solvable by means of computational analysis, so I decided to table that line of thinking for another day. What’s more, I decided to import and apply NLTK’s stopword dictionary to remove from each corpus certain prepositions and conjunctions, which would otherwise convolute bigram and trigram data.
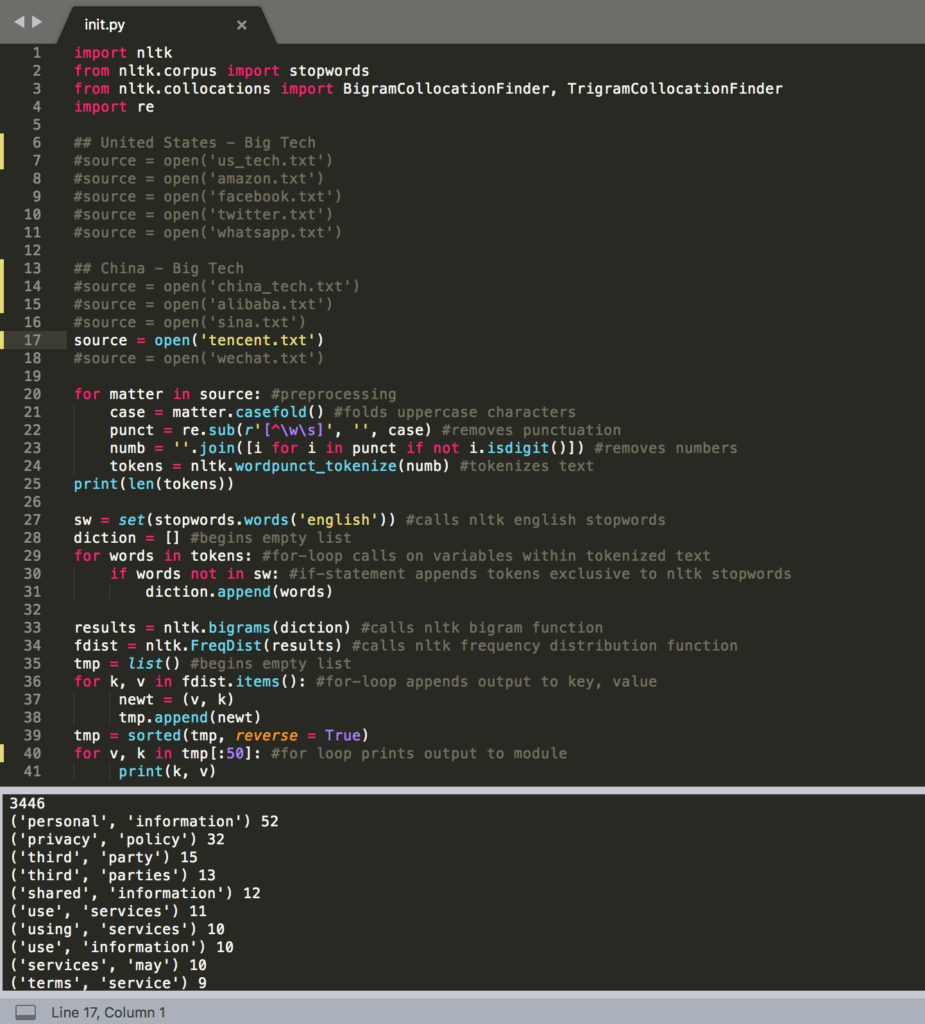
For the sake of transparency, I’ve taken a screenshot of the code I used to retrieve high frequency words, bigrams, and trigrams throughout each corpus. To shift between these three measurements only required that I reassign the identifiers to certain variables, while moving between corpora required that I remove the commented-out code preceding the call to open each file, as with line 17.
Once I migrated the results for each corpus over to Excel, which took longer than I would like to admit, I started probing for patterns between two or three relative datasets but mostly between analogous companies vying for a constituent market, as well as between American and Chinese companies and their subsidiaries. Comparing WhatsApp and WeChat struck me as promising in that either company is a subsidiary application of a much larger multinational conglomerate, both vying to keep their share of the mobile communications market. When first surveying this data, I came to the realization that these privacy policies were not necessarily long enough on their own to yield insightful statistical results. But that isn’t to say they weren’t informative, because they most certainly were. Pulling trigram frequency from the privacy policies for WhatsApp and WeChat alone seemed to me a far more revealing experience than colloquially skimming these documents could ever be. I was struck right away, for one, by the bare repetition by both apps to emphasize the importance of understanding the effect of third-party services on information security. Note, however, that the emphasis is by no means unique to WhatsApp and WeChat: there are 170 total occurrences of ‘third-party’ across my full dataset when the term is normalized into a single word without permutations.
| WhatsApp Privacy Policy | WeChat Privacy Policy | ||
| Sum length: 3489 | Sum length 5019 | ||
| Trigram | Count | Trigram | Count |
| facebook, company, products | 7 | legal, basis, eu | 18 |
| understand, customize, support | 6 | basis, eu, contract | 14 |
| support, market, services | 6 | tencent, international, service | 6 |
| provide, improve, understand | 6 | wechat, terms, service | 5 |
| operate, provide, improve | 6 | understand, access, use | 5 |
| improve, understand, customize | 6 | better, understand, access | 5 |
| customize, support, market | 6 | access, use, wechat | 5 |
| third-party, services, facebook | 5 | third-party, social, media | 4 |
| third-party, service, providers | 5 | provide, personalised, help | 4 |
| services, facebook, company | 5 | provide, language, location | 4 |
| use, third-party, services | 4 | privacy, policy, applies | 4 |
| operate, provide, services | 4 | personalised, help, instructions | 4 |
Perhaps the most noteworthy difference between either app’s privacy policies appears lie in the textual space that WeChat dedicates to covering the legal bases of the European Parliament. (Note: the dataset cites them as “legal basis” as a difference in convention.) Inaugurated with the “The Treaty on the Functioning of the European Union” in 2007, these legal bases more specifically enable the EU precedent to conduct legal action and legislate policy on the grounds of certain predefined issues across Europe. In the WeChat privacy policy, references to “legal bases” follow a section heading on the management of user data, written in an effort to meet specific cases of European international law on personal privacy. Here’s how that section begins, with an example of its subsequent content:

While I don’t claim to be making any fresh discoveries here, I do think it’s interesting to consider the ways in which WeChat qualifies its international link to the EU legal bases by hedging EU protocol with the phrase: “to the extent applicable.” While appearing to satisfy EU legal bases as far as international jurisdiction applies, in other words, WeChat seems to permit itself a more flexible (if vague) standard of privacy for individuals who partake in its services outside the reigns of the European Union. This begs the question of where specifically American users factor into the equation, not to mention whether or not EU-protected users are safeguarded when their personal data crosses international boundaries by communicating with users in unprotected countries. Likewise, another question involves how this matter will impact the U.K. once they’ve successfully parted ways with EU on Jan 31, 2020. Namely, will the legal ramifications of Brexit compromise user data for British citizens who use WeChat? What of applications or products with similar privacy policies as WeChat? Scaling this thread back to Tencent, I was somewhat surprised to find little to no explicit mention of the EU in the top 30 word, bigrams, and trigrams. However, I did notice that tied for the 30th most frequent bigram, with four occurrences, was “outside, jurisdiction.” Searching through the unprocessed text document of Tencent’s privacy policy, this bigram led me to a statement consistent with the WeChat’s focus on EU legal bases, excerpted below. (Bolded language is my own.)
You agree that we or our affiliate companies may be required to retain, preserve or disclose your Personal Information: (i) in order to comply with applicable laws or regulations; (ii) in order to comply with a court order, subpoena or other legal process; (iii) in response to a request by a government authority, law enforcement agency or similar body (whether situated in your jurisdiction or elsewhere); or (iv) where we believe it is reasonably necessary to comply with applicable laws or regulations.
So, while EU legal bases play no explicit role in the multinational’s broader privacy policy, such legal protocol nonetheless seems to play a role, though again only when relevant — or, at least in this case, “where [they] believe it is reasonably necessary to comply applicable laws or regulations.” It was at this point that I started to consider the vast array of complexity with which multinational conglomerates like Tencent compose primary and secondary privacy policies in an effort to maximize information processing while also protecting their company and its subsidiary products from legal action. In turn, I began to consider new and more focused ways of examining these privacy policies in terms of their intelligibility/readability as textual documents.
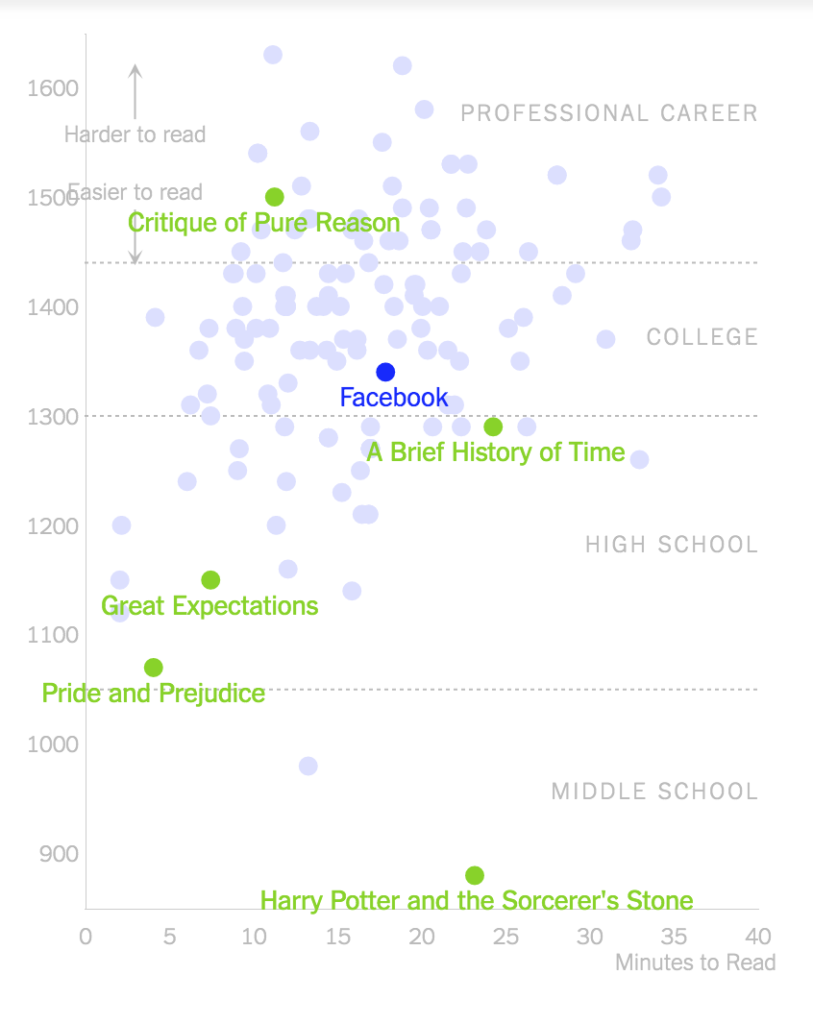
This question led me to discover the following NYT article by Kevin Litman-Navarro on privacy policies written by major tech and media platforms that “opaquely establish companies’ justifications for collecting and selling your data” with their difficulty and verbosity of language. Using the Lexile test to determine a text’s complexity, Litman-Navarro analyzes a flurry of some odd 150 privacy policies, some of which are included in my dataset, such as Facebook, which his evaluation determines to be somewhere between The Critique of Pure Reason by Immanuel Kant (most difficult) and A Brief History of Time by Stephen Hawkings (more difficult) in its range of readability. Meanwhile Amazon’s privacy policy, whose word count totaled at 2624 as opposed to Facebook’s heftier 4203 words, was between A Brief History of Time and Great Expectations by Charles Dickens.
| Privacy Policy | Lexical Diversity |
| 5.598529412 | |
| 5.237951807 | |
| 5.120921305 | |
| 5.027633851 | |
| Alibaba | 4.779365079 |
| Tencent | 4.627151052 |
| Amazon | 4.276679842 |
| Sina Weibo | 3.184115523 |
In an attempt to replicate a similar sense of these results, I employed NLTK’s measurement of lexical diversity and recorded my statistical results to the right. If lexical diversity is any indication of readability, then it seems as if these results reflect part and parcel of Litman-Navarro’s analytics, with Twitter indicating a higher diversity index than Facebook, which in turn indicates a higher diversity index than Amazon.
Considering the size of my dataset, I think moving forward it might be best to simply link it here for those who are themselves interested in interpreting the qualitative results of these privacy policy texts. Ultimately, I see my project here as the groundwork for a much large, more robustly organized study of these legal documents. There’s tons and tons of data to be unearthed and analyzed when it comes to the microscopic trends of these legal documents, particularly when placed against the backdrop of a much grander scale and sample size. Whereas I’ve picked my corpora on a whim, I think a more cogent and thoroughgoing inquiry into these documents would merit hundreds of compiled privacy policies from tech and media companies across the world. A project worth pursuing someday soon indeed…