One of the more difficult steps of putting together my syllabus was coming to terms with the theme of my class. On one level, I knew I had to choose a theme that would contain readings in the public domain, but I also want to choose a topic that would fit well into a collection once edited together and uploaded into Manifold. All things considered, I decided to go with what I call “short-form prose,” which allowed me to include a multigenre selection of readings ranging from fiction and poetry, to letters and essays, to aphorisms and satire, to sundry blends of social media. When I came to the course schedule, though, I suddenly realized that I would have to bring together a broad range of readings in order to properly represent each of these genres of prose. More than anywhere else, this is where I spent the vast majority of my time, combing the internet for readings from authors like Franz Kafka and O. Henry, William Carlos Williams and Jean Toomer, Simone de Beauvoir and Oscar Wilde, Michel de Montaigne and Jonathan Swift, if only to name a few. I even decided to include koans, which serve to counterpoint aphorisms by Johann Wolfgang von Goethe. The process was long and onerous. It was also intensely gratifying.
Additionally, I structured the first major writing assignment of my syllabus, the Close-Reading Analysis, so that students will have an opportunity to peer-review each other’s essays before handing in their final copy. Even then, each student will have as many chances as they please to revise and submit their paper once they receive back their initial grade. Indeed, with the second major writing assignment, the Research Paper, they are required to revise and resubmit their first draft, this time receiving feedback from their peers prior to their second submission. In both cases, only the grade of their last and final submission will count. Beyond the confines of the traditional academic essay, I also designed my syllabus to include low-stakes writing assignments by way of formal emails and self-reflective blogs. It is of no small importance that these writing activities enable student to scaffold their rhetorical identity on the page, while also preparing them for public-facing writing practices that are essential to their future academic success.
I had a blast with this final project. It was challenging and time-consuming to the point of exacerbation, but the process was also surprisingly redemptive once I saw that final product sitting there in front of me. Mind you, one lesson I can almost certainly promise to have learned: I’ll never skim another professor’s syllabus ever again.
Having appreciated our reading from Digital Sound Studies, I wanted to first vouch for the keen way in which the book’s editors introduce readers to this rising field of multimodal inquiry, often striking a balance between the ethical and intellectual currents of sound-centric inquiry. As difficult as it is to initiate readers to new types of criticism, the act of presenting a radical new mode of scholarship altogether is truly another beast, not least because the academy is known for clinging to its standards in communication and praxis. Lingold, Mueller, and Trettien problematize this matter when discussing the disciplinary origins of the digital humanities, in particular, writing that the “answer lies in the text-centricity of the field, a bias that is baked into its institutional history,” borne out by text-based journals like Literary and Linguistic Computing and social media platforms like Twitter (10). Given that text-centricity permeates academic knowledge production and thus shapes the disciplinary ethos of DH, I suspect the field cannot afford to overlook multimodal initiatives without continuing to suffer from the tacit biases of text-centric thinking. With that said, I’m immediately inclined to point out the elephant in the room by noting that the text-centered format of my blogpost is an irony not lost on me. It is actually in light of acknowledging this irony that I’ve decided to use this post as a space to not only think about but also try out some of the critical methods outline in the introduction to Digital Sound Studies.
Accordingly, one train of thought and practice that I’m interested in pursuing here relates to “what counts as “sound” or “signal” and what gets dismissed as “noise”… across listening practices,” focusing perhaps on how certain sounds inscribe meaning into our unselfconscious experience of digital tools and social spaces (5). Broadly speaking, the myriad sounds of digital technology run the gamut in how they signify meaning to users. For instance, on one end of the digital spectrum, we have the bubbly sound effect that Facebook emits when aggregating user feeds, all but patching its simulation of our “real-time” social community. Meanwhile, on the other end, we have the IBM beep codes of a power-on self-test (POST), configured so that computer systems will self-assess for internal hardware failures and communicate their results to users (who in return seldom think twice). Fascinating as cybernetics can be, I’ve found myself even more drawn to analyzing how this hypercritical approach to digital sounds can shed light our experience of the relation between sound and noise in daily routines.
Take, for example, my daily commute. Inauspiciously swiping my MetroCard yesterday, I came across the dreaded beeping sound of a turnstile failing to register my magnetic strip, joyously accompanied by that monochromatic error message which politely requests tepid MTA riders to Please swipe again or Please swipe again at this turnstile. As residents of NYC, it’s a sound effect we know too well — and yet I decided to record and embed it below, along with the next 90 or so seconds of this Monday morning commute to Manhattan.
https://soundcloud.com/zmuhlbauer1/mta-voiceover
The recording then teeters about for a moment until the rattling hum of the train grows more and more apparent. After grinding to a stop, its doors hiss open, the MTA voiceover plays, and I enter the subway car to find the next available seat.
Though straightforward at a glance, many of these sounds work not unlike commas in a CSV file, similarly but more loosely enacting delimiters for one of the key duties of the NYC subway system: to safely prompt passengers onto and out of subway cars. Together with verbally recorded cues, in other words, MTA voiceovers appear to serve as markers of not only spatial but also temporal cues. By way of example, consider the following series of sound signals: the turnstile’s beep effect marks a transition into the self-enclosed space of the station; the M-train arrives and emits its door-opening voiceover, which at once marks the line progression and the onset of when riders may enter the train, framed off by the (in)famous MTA line, Stand clear of the closing of the closing doors please. Exiting the train, I was struck by the fact that I had only twice acknowledged the sound of the voiceover (getting on at Hewes Street and getting off at Herald Square station), despite there being several other stops between. It follows that these sound effects contain locally assigned meaning, produced in accordance with the intentionality or focus of the subject — or, in this case, the individual passenger. Herein lies the difference between sound and noise. We inscribe symbolic value to sound on the basis of perceived relevance, of functional utility, but have no immediate use for noise, which in turn blends into white noise, accounting for why sound is specific and noise nonspecific. Put differently, we choose to hear certain sounds because they are unsurprisingly meaningful to us and our purposes — e.g. hearing your name in a crowd — while we neglect the indiscrete stuff of noise because it is peripheral, useless. While sound resembles our impressions of order, noise veers closer to our impressions of disorder.
Exiting the train, I was struck by the fact that I had only twice acknowledged the sound of the voiceover (getting on at Hewes Street and getting off at Herald Square station), despite there being several other stops between. It follows that these sound effects contain locally assigned meaning, produced in accordance with the intentionality or focus of the subject — or, in this case, the individual passenger. Herein lies the difference between sound and noise. We inscribe symbolic value to sound on the basis of perceived relevance, of functional utility, but have no immediate use for noise, which in turn blends into white noise, accounting for why sound is specific and noise nonspecific. Put differently, we choose to hear certain sounds because they are unsurprisingly meaningful to us and our purposes — e.g. hearing your name in a crowd — while we neglect the indiscrete stuff of noise because it is peripheral, useless. While sound resembles our impressions of order, noise veers closer to our impressions of disorder.
To further ground my thoughts in the context of DH and digital sound studies, also consider the interrogative voice at the end of the recording from above. As some might guess, once the MTA voiceover begins to fade out, the recording very clearly catches a homeless man’s appeal for food from passengers on the train. Intending initially to catch clearly recorded sounds of the MTA subway system, my knee-jerk reaction here was to either edit the file (the one embedded above), or to simply cut my losses and rerecord when returning home later that day. Since it felt heavy-handed to run through the whole process again and convolute the integrity of my data-collection process, I elected to edit the video at first. But it was only shortly after that I started to think more honestly about why I wanted to record my commute in the first place. In turn, I determined that this interruption did not misrepresent my commute so much as it merely deviated from what I anticipated — and thus intended — to record out of my commute, if only to realize the extent to which these these interrogative sounds were crucially embedded in my experience of the ride and its sounds. No amount of edit will change that fact, so here below I’ve included the full recording:
Needless to say, sudden appeals for food or money on these tight subway cars can have an awkward or troubling effect on passengers, who in return may go quiet, look down or away, resort to headphones, or read absently until it’s over. As is common, the man in this recording recognizes this particular social reality, evident in how he prefaces his appeal by saying “I’m really sorry to disturb you.” Similar to the many for whom this experience is semi-normalized, I’m inclined to likewise ignore these interruptions for the same reason that I rushed to edit my recording in pursuit of an uninterrupted soundbite — that is, because I’m regulated to perceive these appeals as just another unavoidable case of NYC noise, brushed off as an uncomfortable glitch in the matrix of urban American society.
Like “the cats batting at Eugene Smith’s microphone” and refocusing listeners to “the technology itself,” it’s clear that such disturbances enable us to reinspect our use of digital technology, often in ways that reveal the naturalized conditions of daily social life and more (3). I cannot help but think back to the part of Race After Technology when Ruha Benjamin speaks to the illuminating potential of digging deeper into glitches; and how these anomalies can act as key resources in the fight to reveal hidden insights about the invisible infrastructures of modern technology. With that in mind, I’ll end with an excerpt of hers, one whose words to me ring a little louder today than they did in days prior.
Glitches are generally considered a fleeting interruption of an otherwise benign system, not an enduring and constitutive feature of social life. But what if we understand glitches to be a slippery place (with reference to the possible Yiddish origin of the word) between fleeting and durable, micro-interactions and macro-structures, individual hate and institutional indifference? Perhaps in that case glitches are not spurious, but rather a kind of signal of how the system operates. Not an aberration but a form of evidence, illuminating underlying flaws in a corrupted system (80).
In the DH spirit of openness — and to offer you all a more complete idea of the syllabus I intend to design for our final project — I thought it might be worthwhile to post my one-page prospectus on our blog. Please do let me know your thoughts and suggestions!
A Manifold Syllabus
Open Educational Resources, Readings, and Textuality in the First-Year Writing Classroom
In preparing to serve as a writing instructor for Baruch College in Fall 2020, I hope to deploy this project as a chance to envision a syllabus whose pedagogy encourages students to unite their reading, writing, and digital literacies toward a generative, multimodal learning experience. Aiming to promote a more intuitive and transactional relationship between reader and text, I plan to collate each of my assigned readings into a single .epub file formatted according to Manifold’s publication interface, with each “chapter” delimited by individual class readings drawn solely from the public domain. With each chapter sequenced in tandem with the linear flow of my syllabus, I intend for this remixed digital publication to afford students a more streamlined, yet cohesive interaction with the course’s assigned readings. In addition, I plan to incorporate Manifold’s annotative toolkit into the “Participation” component of my syllabus, requesting that students post 2-3 public comments on one of the two assigned readings for a given class. Each set of annotations will not only help precondition a space for class discussion, but they will also structure the course’s three critical self-reflections, which will prompt students to choose an assigned reading for informal analysis by situating their comments in conversation with those of their classmates. These critical self-reflections will work up to a six-page academic research paper, thematized according to argumentative topics chosen by students in a participatory poll on the matter. Adopting a process-based model of pedagogy, I plan to offer students constructive feedback on their first draft of this writing assignment, in conjunction with a preliminary grade to be overridden by the grade I later assign to their final drafts. In order to unpack my syllabus into a more substantial pedagogical framework, moreover, my proposal will utilize academic scholarship on topics ranging from critical writing studies, to multimodal theories of literacy, to a student-centered pedagogy of praxis.
With our class having recently discussed our collective frustration and ignorance toward the terms and conditions of “Big Tech” companies, I felt it worthwhile to take a look at the privacy policies of major technology corporations — and some of their subsidiary digital platforms — in not only the United States, but also China. Part of my reasoning behind this international perspective on the tech sector draws from an interest in probing at some of the similar and disparate ways in which major American and Chinese tech companies articulate their terms and conditions regarding the management of user privacy and personal data. At the onset of my project, I didn’t necessarily have a concrete grasp on what sort of trends I expected to find, but I also felt as though this uncertainty might lend itself to a few hidden insights given that I to some extent let the data do the talking. Situating myself in the playful spirit of to “the hermeneutic of screwing around,” vis-a-vis Stephen Ramsay, I wanted to poke around inside of these deconstructed corporate texts, to unravel their legalese and consolidate it into a dataset, picking and prodding at trends in their diction, syntax, and structure. Meanwhile, I thought it important to keep an eye out for subject matter that might have otherwise gone unacknowledged by 91% of users when checking the proverbial box: the vast majority of us consumers who at the mere sight of these ghastly documents choose to throw our arms in the air before abruptly agreeing to the terms and conditions.
In the spirit of normalizing failure and learning from past mistakes, I’d like to note that my ambition exceeded my grasp when first gathering text corpora for this project, if only because I started by compiling data on individual privacy policies and service agreements from Amazon, Facebook, and Twitter, as well as Alibaba, Sina Weibo, and WeChat. This entailed that I gather twelve total files for text analysis in Python. I intended to analyze each file for three specific linguistic measurements — term frequency, bigram frequency, trigram frequency — which, as far as Excel columns go, meant multiplying twelve times six due to the fact that each corpus requires three columns for its key (e.g. “privacy, notice”) and three columns for its value (e.g. “9”) Suddenly the number of columns of data in my spreadsheet ballooned to 72, which of course is too much data for one person to qualitatively parse in a limit time span. Needless to say, I had some reflecting to do.
In writing code to preprocess these text files, I decided to clean house on punctuation, uppercase characters, as well as integers. These alterations are not without ambivalence. Indeed, I think there are salient insights hidden among the use of numbers across these corpora. For one, these documents are written in a legal register that so happens to self-reference numbered sections with its own set of terms and conditions, disclosed earlier or later in a given document. While robust on a legal level, this technique doesn’t exactly enhance readability despite the fact that these documents are explicitly meant for consumers who must in turn agree with its obtuse parameters. In any case, these documents don’t self-reference themselves via numbered sections so often that it becomes a problem solvable by means of computational analysis, so I decided to table that line of thinking for another day. What’s more, I decided to import and apply NLTK’s stopword dictionary to remove from each corpus certain prepositions and conjunctions, which would otherwise convolute bigram and trigram data.
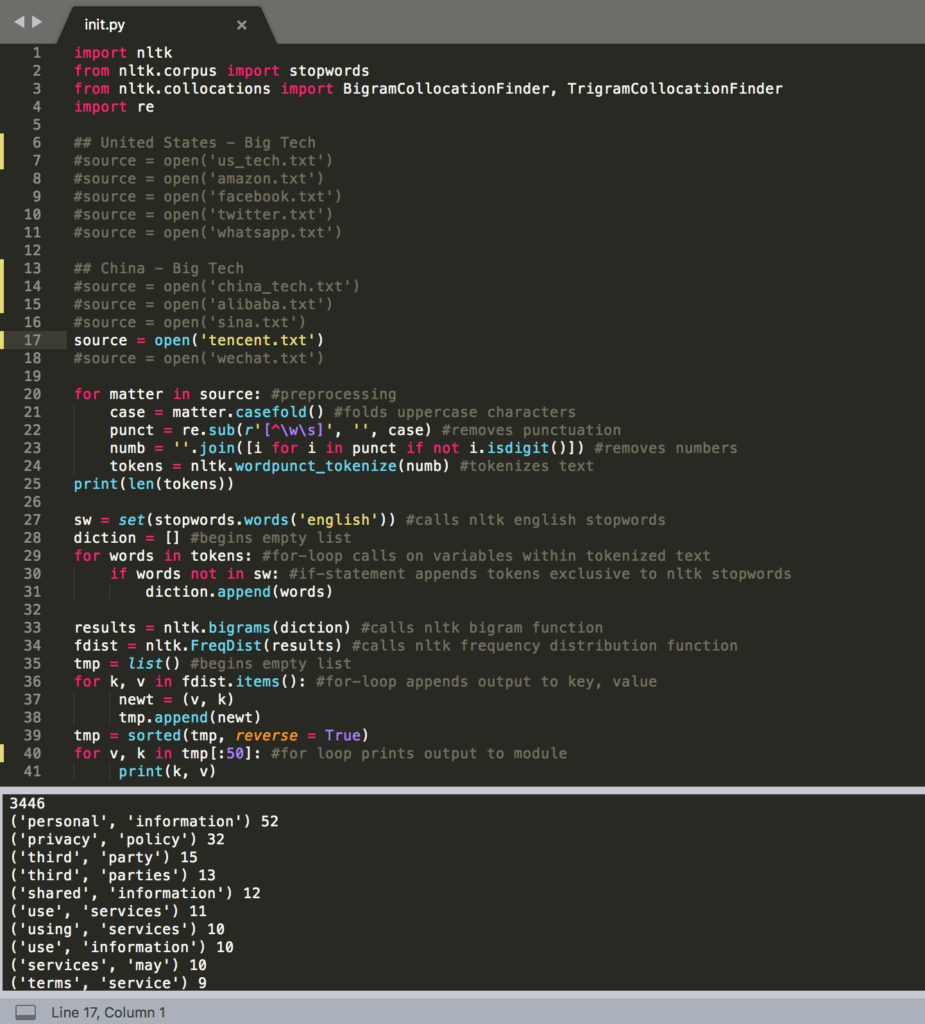
For the sake of transparency, I’ve taken a screenshot of the code I used to retrieve high frequency words, bigrams, and trigrams throughout each corpus. To shift between these three measurements only required that I reassign the identifiers to certain variables, while moving between corpora required that I remove the commented-out code preceding the call to open each file, as with line 17.
Once I migrated the results for each corpus over to Excel, which took longer than I would like to admit, I started probing for patterns between two or three relative datasets but mostly between analogous companies vying for a constituent market, as well as between American and Chinese companies and their subsidiaries. Comparing WhatsApp and WeChat struck me as promising in that either company is a subsidiary application of a much larger multinational conglomerate, both vying to keep their share of the mobile communications market. When first surveying this data, I came to the realization that these privacy policies were not necessarily long enough on their own to yield insightful statistical results. But that isn’t to say they weren’t informative, because they most certainly were. Pulling trigram frequency from the privacy policies for WhatsApp and WeChat alone seemed to me a far more revealing experience than colloquially skimming these documents could ever be. I was struck right away, for one, by the bare repetition by both apps to emphasize the importance of understanding the effect of third-party services on information security. Note, however, that the emphasis is by no means unique to WhatsApp and WeChat: there are 170 total occurrences of ‘third-party’ across my full dataset when the term is normalized into a single word without permutations.
WhatsApp Privacy Policy
WeChat Privacy Policy
Sum length: 3489
Sum length 5019
Trigram
Count
Trigram
Count
facebook, company, products
7
legal, basis, eu
18
understand, customize, support
6
basis, eu, contract
14
support, market, services
6
tencent, international, service
6
provide, improve, understand
6
wechat, terms, service
5
operate, provide, improve
6
understand, access, use
5
improve, understand, customize
6
better, understand, access
5
customize, support, market
6
access, use, wechat
5
third-party, services, facebook
5
third-party, social, media
4
third-party, service, providers
5
provide, personalised, help
4
services, facebook, company
5
provide, language, location
4
use, third-party, services
4
privacy, policy, applies
4
operate, provide, services
4
personalised, help, instructions
4
Perhaps the most noteworthy difference between either app’s privacy policies appears lie in the textual space that WeChat dedicates to covering the legal bases of the European Parliament. (Note: the dataset cites them as “legal basis” as a difference in convention.) Inaugurated with the “The Treaty on the Functioning of the European Union” in 2007, these legal bases more specifically enable the EU precedent to conduct legal action and legislate policy on the grounds of certain predefined issues across Europe. In the WeChat privacy policy, references to “legal bases” follow a section heading on the management of user data, written in an effort to meet specific cases of European international law on personal privacy. Here’s how that section begins, with an example of its subsequent content:
While I don’t claim to be making any fresh discoveries here, I do think it’s interesting to consider the ways in which WeChat qualifies its international link to the EU legal bases by hedging EU protocol with the phrase: “to the extent applicable.” While appearing to satisfy EU legal bases as far as international jurisdiction applies, in other words, WeChat seems to permit itself a more flexible (if vague) standard of privacy for individuals who partake in its services outside the reigns of the European Union. This begs the question of where specifically American users factor into the equation, not to mention whether or not EU-protected users are safeguarded when their personal data crosses international boundaries by communicating with users in unprotected countries. Likewise, another question involves how this matter will impact the U.K. once they’ve successfully parted ways with EU on Jan 31, 2020. Namely, will the legal ramifications of Brexit compromise user data for British citizens who use WeChat? What of applications or products with similar privacy policies as WeChat? Scaling this thread back to Tencent, I was somewhat surprised to find little to no explicit mention of the EU in the top 30 word, bigrams, and trigrams. However, I did notice that tied for the 30th most frequent bigram, with four occurrences, was “outside, jurisdiction.” Searching through the unprocessed text document of Tencent’s privacy policy, this bigram led me to a statement consistent with the WeChat’s focus on EU legal bases, excerpted below. (Bolded language is my own.)
You agree that we or our affiliate companies may be required to retain, preserve or disclose your Personal Information: (i) in order to comply with applicable laws or regulations; (ii) in order to comply with a court order, subpoena or other legal process; (iii) in response to a request by a government authority, law enforcement agency or similar body (whether situated in your jurisdiction or elsewhere); or (iv) where we believe it is reasonably necessary to comply with applicable laws or regulations.
So, while EU legal bases play no explicit role in the multinational’s broader privacy policy, such legal protocol nonetheless seems to play a role, though again only when relevant — or, at least in this case, “where [they] believe it is reasonably necessary to comply applicable laws or regulations.” It was at this point that I started to consider the vast array of complexity with which multinational conglomerates like Tencent compose primary and secondary privacy policies in an effort to maximize information processing while also protecting their company and its subsidiary products from legal action. In turn, I began to consider new and more focused ways of examining these privacy policies in terms of their intelligibility/readability as textual documents.
Litman-Navarro, Kevin. “We Read 150 Privacy Policies. They Were an Incomprehensible Disaster.” Opinion. The New York Times. 12 June 2019.
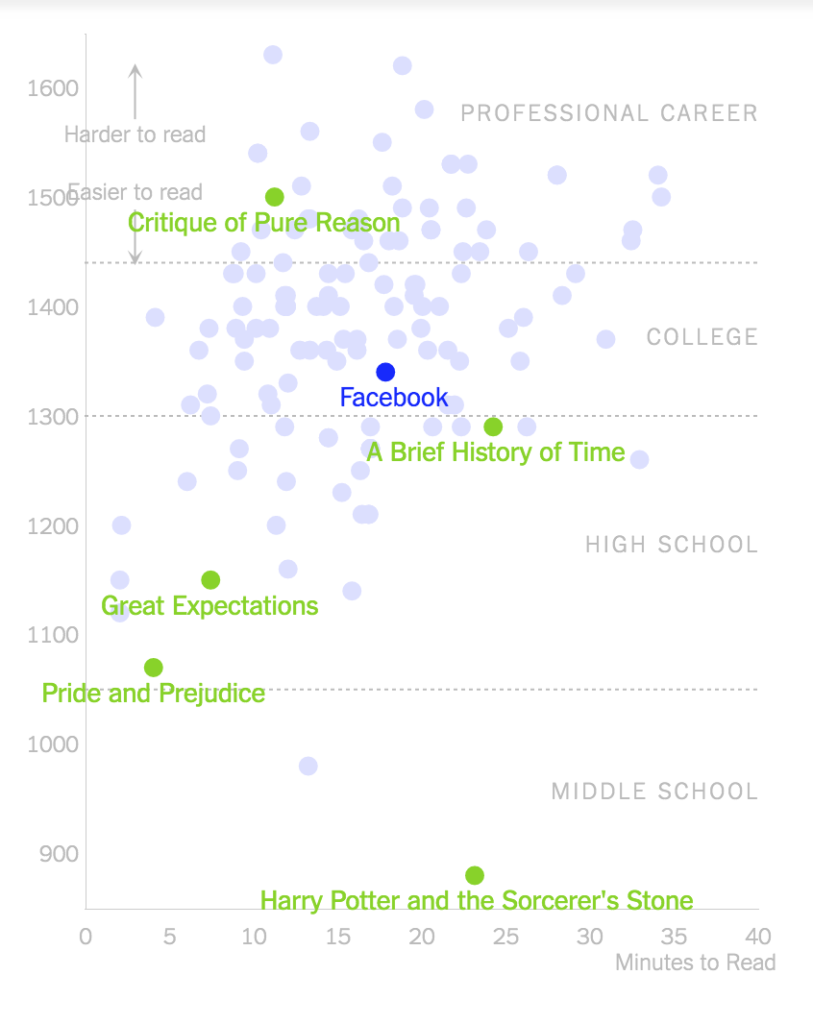
This question led me to discover the following NYT article by Kevin Litman-Navarro on privacy policies written by major tech and media platforms that “opaquely establish companies’ justifications for collecting and selling your data” with their difficulty and verbosity of language. Using the Lexile test to determine a text’s complexity, Litman-Navarro analyzes a flurry of some odd 150 privacy policies, some of which are included in my dataset, such as Facebook, which his evaluation determines to be somewhere between The Critique of Pure Reason by Immanuel Kant (most difficult) and A Brief History of Time by Stephen Hawkings (more difficult) in its range of readability. Meanwhile Amazon’s privacy policy, whose word count totaled at 2624 as opposed to Facebook’s heftier 4203 words, was between A Brief History of Time and Great Expectations by Charles Dickens.
Privacy Policy
Lexical Diversity
WeChat
5.598529412
Twitter
5.237951807
WhatsApp
5.120921305
Facebook
5.027633851
Alibaba
4.779365079
Tencent
4.627151052
Amazon
4.276679842
Sina Weibo
3.184115523
In an attempt to replicate a similar sense of these results, I employed NLTK’s measurement of lexical diversity and recorded my statistical results to the right. If lexical diversity is any indication of readability, then it seems as if these results reflect part and parcel of Litman-Navarro’s analytics, with Twitter indicating a higher diversity index than Facebook, which in turn indicates a higher diversity index than Amazon.
Considering the size of my dataset, I think moving forward it might be best to simply link it here for those who are themselves interested in interpreting the qualitative results of these privacy policy texts. Ultimately, I see my project here as the groundwork for a much large, more robustly organized study of these legal documents. There’s tons and tons of data to be unearthed and analyzed when it comes to the microscopic trends of these legal documents, particularly when placed against the backdrop of a much grander scale and sample size. Whereas I’ve picked my corpora on a whim, I think a more cogent and thoroughgoing inquiry into these documents would merit hundreds of compiled privacy policies from tech and media companies across the world. A project worth pursuing someday soon indeed…
This past Monday, Nov. 4, I attended an ITP workshop entitled, “Multimodal & Game-based Pedagogy,” led by Kahdeidra Martin, who proved to be a kind and enthusiastic steward into the world of student-centered praxis. The crux of the workshop involved integrating cutting-edge learning theories with hands-on pedagogical methods, in turn marrying theory and practice so as to facilitate a more intuitive, learner-centric approach to instructional design.
Kahdeidra began her workshop by requesting all participants to find a partner for a word-association game, in which each team chose two words from a bank of indigenous terms and proceeded to reel off as many associated words as possible within a limited time-span. We then went on to reflect on how this process inspired us to think collaboratively about the game-based logic of word association — which itself amounted to a fascinating conversation about the value of team-based, generative learning prompts. From there, Kahdeidra spoke about how teachers today might benefit from the practice of situating learning concepts and outcomes in the context of constructive game-based activities.
What’s more, Kahdeidra focused on the evidence-based value of student-centered pedagogy, citing an array of research from cognitive science on how communal and active learning experiences often serve to motivate student in ways that transmissionist pedagogy does not. Some of the key elements of student-centered pedagogy, Kahdeidra clarified, involve inquiry-based activities, strategic grouping and reciprocal learning, distributed knowledge production, as well as a personalized and interactive sense of student agency. At the center of these elements, we concluded, lies an impetus to tailor learning outcomes to actual student needs rather than pre-established lesson plans.
We further discussed how, in order to afford attention to learner needs, teachers ought to allow their students multiple points of access beyond that of a solitary text-based modality. Underpinning this approach to instructional design are two educational frameworks, both of which date to recent developments in cognitive neuroscience: namely, multiple intelligence theory (MI) and universal design for learning (UDL). Either framework confirms that using multiple entry points to attain knowledge demonstrates an equitable yet effective way to engage a diverse range of learners. Correspondingly, Kahdeidra cited scholars in demonstrating the manner in which “learning activities that include repetition and multiple opportunities to reinforce learning support brain plasticity, the continuous ability to adapt to new experiences” (Singer 1995; Squire & Kendel 2009). Using MI and UDL as a theoretical springboard for the rest of her workshop, Kahdeidra then provided each team with the handout below, otherwise known as the Martin Multimodal Lesson Matrix (TAPTOK):
After explaining these categories and how they constellate to enable an interactive learning experience for students, Kahdeidra asked each team to annotate one of her lesson plans with TAPTOK in mind. A fascinating question that subsequently emerged concerned the extent to which we as instructors can fit these categories into one cohesive learning activity without overwhelming students. In reply, Kahdeidra thoughtfully noted that the multimodal categories one employs will depend on the the nature of the subject matter and its associated learning outcomes. Put differently, it is invaluable for instructors to recognize, given the subject matter and time-constraints of their lesson, which multimodal categories might best facilitate dynamic and engaged learning habits, and which may rather serve as a distraction to students.
We discussed related topics, like Gee’s 16 principles for good game-based learning and Vygotsky’s zone of proximal development, but I’d like to wrap up at this point by expressing excitement over the contents of this workshop. Student-centered pedagogy, particularly in the context of game-based and multimodal learning, seems to me an important and valuable step forward for postsecondary education. The process of teaching is not about the teacher; it is about the student, the learner. I am confident this credo is one worthy of our attention — and so deserves our vested support and implementation if it is to eventually become a standard instructional practice of future educators. That said, multimodal and game-based learning only seem to be the tip of the iceberg, if only because student-centered pedagogy is so much more than a set of methods or practices: it is a mindset, a disposition, an enduring sign of respect for the learners we aim to enrich and support in these trying times.
I. The premise for my mapping project draws its inspiration from our running class dialogue about the complicated ways in which we must all negotiate our subjectivity when leveraging digital software and tools to design and build maps. So, in approaching the praxis mapping assignment, I found that my core aim was to wrestle with the interplay between subject/object by integrating cartographic methods with monochromatic photography, in turn juxtaposing the overhead vantage point of traditional cartography with the first-person standpoint and embeddedness of photography. Intending to embrace a more reflexive and intimate approach to mapping, in other words, I wanted to challenge traditional cartography by considering the means by which a series of photographs could invite viewers to craft their own personal visual narrative about a geographic space. While I feel as though my project involves more aesthetic ways of knowing than the propositional or analytic epistemologies of traditional mapping methods, I still want to recognize the fact that this approach nevertheless depends on those same cartographic conventions, otherwise I wouldn’t have a prearranged map of Williamsburg to plot each of my black and white photos. I also want to note that while I cannot wholly unlearn the biases or inclinations of my eye as an amateur photographer, I did make a self-conscious effort to capture a wide array of material, ranging from traffic lights and church spires, to convenience stores and ripped fliers, to flagpoles and local graffiti. Taking the urban landscape of Williamsburg as my priority, and with late-stage gentrification as a key thematic focus in my daily routes, I ultimately elected not to embed any photographs of people, if only because I did not want to exploit their likeness for the sake of my project or its associated narratives. (Admittedly, I am also not too skilled at portrait photography.)
II. With the vast majority of us having combed through our fair share of Google Street View, I think I can speak for most people when I say that these photos are decidedly austere in their ~25,500TB attempt at rendering an “immersive geography” of the world, which is to say, the industrial world. To some extent, given the parameters of Google’s on-the-ground approach to cartography, this spare style is understandable and even somewhat expected, but I nonetheless feel as though it is important to the note that the Lovecraftian deity of Google did not shoot these photographs wholesale; rather, these interactive VR panoramas are only possible due to a process called image stitching, in which computer software quilts together an overlapping array of adjacent photographic images. Part of the inspiration for my map plays on this Big Data concept of global mastery — i.e. via capturing and showcasing a three-dimensional rendering of our local “street view” experience of the world — by photographing and mapping Williamsburg through the subjective vision of a single digital camera.
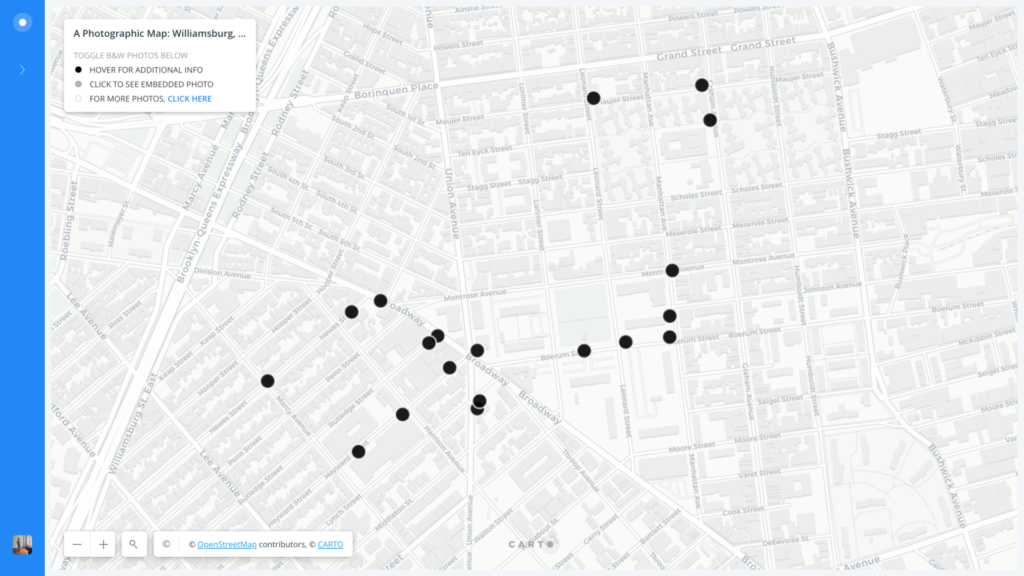
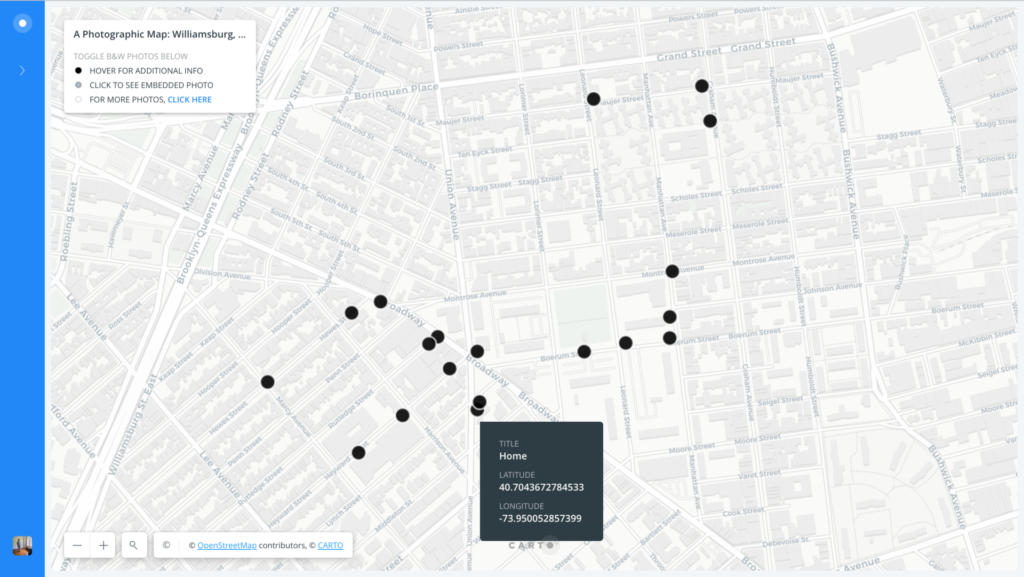
III. The offer a visual overview of my photographic map of Williamsburg, built more specifically with CartoDB, I’ve embedded three annotated screenshots below in order to demonstrate the visual identity of my map as it stands now.
So far, I have plotted a total of 19 locations (and counting), each of which is represented by a black dot. I am hoping to expand the circumference of these plotted locations in order to better represent the eclectic, yet gentrified array of urban terrain that Williamsburg has to offer. Hovering over one of the plotted locations reveals basic information about the title of my photograph, as well as its latitude and longitude. Clicking one of the plotted locations will then reveal its associated black & white photograph, accompanied by a title.
IV. I see this project as a continual work-in-progress — one without an end in sight. In my mind, it is iterative, open to any and all collaborative efforts, reserved to a running state of flux and revision. As we seem to recognize as a class, maps are never subject to completion because the mere concept of “completion” in cartography is a representative fiction — or, better yet, an ever-persistent fantasy of corporate, colonial, and/or national hegemony. As far as my efforts go, in other words, I see this map as a draft in its beginning, ever in process and never quite complete.
The visualized layout of Torn Apart struck me as a salient instance in which DH practices work to graphically negotiate the buried narratives of recent diasporas, while also resisting the urge to classify its scholarly approach under an explicit theoretical framework. This sort of praxis seems to echo how David Scott invites his readers to “think Caribbean studies” by means of persistent inquiry, without necessarily expecting a categorical “answer” on the other end of such questioning. “The point (political, conceptual, disciplinary, moral of mobilizing this image,” or questioning, as Scott claims, seems more contingent upon the unraveling effect that investigative thinking can have on a postcolonial field of inquiry like Caribbean studies. To that point, visualizations such as Torn Apart, I believe, typify scholarship as process: they resist any clear-cut theoretical language, often defined by “foreign” powers; and instead illustrate data in such a way as to encourage its audience to construct their own critical narrative about how, at least in this case, current American power structures like ICE (and their moneyed interests) work to subjugate underrepresented migratory groups. I think the potential for constructing these narratives may lie, for instance, in the nexus between two or more separate data points, as in the case of donors from seemingly distinct political domains. But ultimately there is immeasurable room of critical inquiry amid an accessible dataset like Torn Apart, which is most certainly a virtue when it comes to unraveling the veiled workings of political hegemony in this day and time.
Need help with the Commons?
Email us at [email protected] so we can respond to your questions and requests. Please email from your CUNY email address if possible. Or visit our help site for more information: