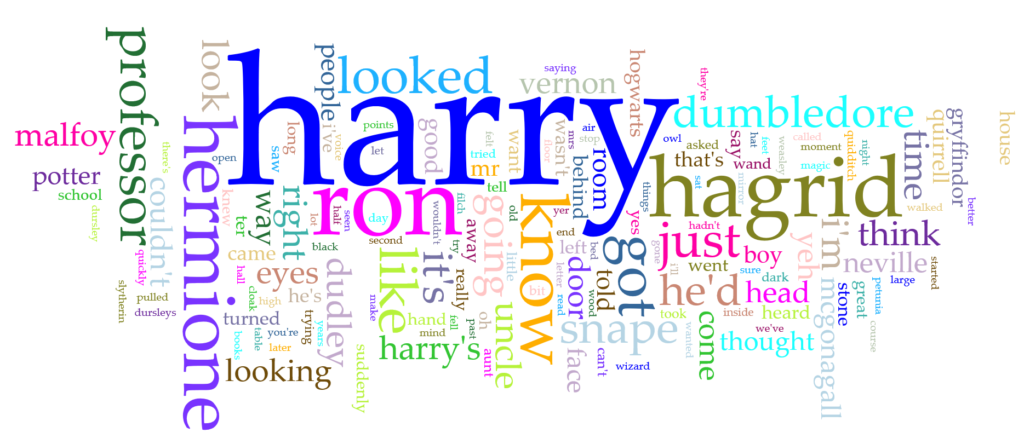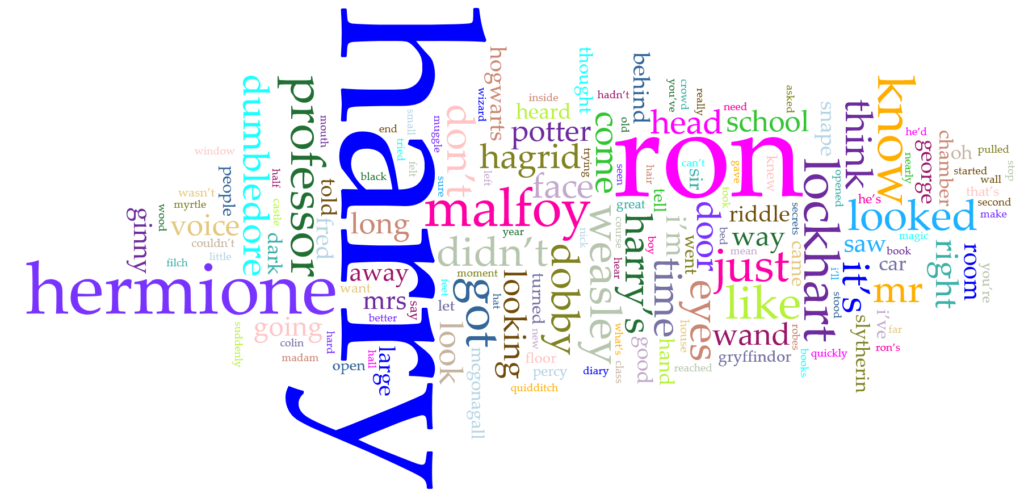The idea for the Text Analysis praxis assignment came after trying to do the Data Visualization praxis assignment a few weeks ago. I had originally planned to do the Data Viz praxis, but I was having trouble finding a dataset or even something that I was interested in using. Unlike the Mapping praxis, I did not have an immediate topic in mind that would allow me to understand my dataset enough to create visualizations in the way I wanted to. Thus, I decided to forego the Data Viz praxis and focus on this week’s Text Analysis praxis.
The first thing I had to think about was what large text I was interested in enough to analyze. Not only would I have to be interested in the topic, it had to be easy enough to get access to the text itself. The first thing that came to mind that I was interested in that would also be easy to access the text was the Harry Potter book series. With the popularity of the text, I knew that I would be able to find the text somewhere online and I know the text enough to be able to spot some interesting patterns.
The tool that I used was Voyant because, from sampling a few of the different tools, I realized that it was, not only easy to use, but had many ways of looking at the text. This was also, unfortunately, determined by the fact that I knew I would not have much time over the past few weeks due to work to mess with other techniques using coding (such as Python), though I was very tempted.
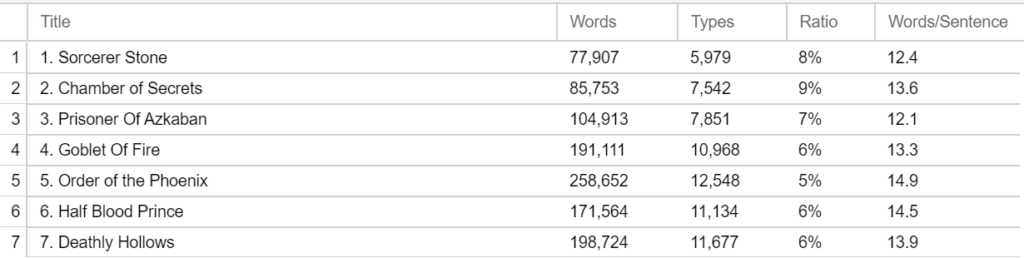
I found each book in the form of a text file and saved them separately. The first thing that I did when I downloaded the text files was to make sure that some items were consistent across all the files. This includes the following:
- Making sure all chapter numbers were spelled out instead of numerical (i.e. Chapter 4 would be changed to “Chapter Four”)
- Making sure that there was no other text except
that of the book.
- For example, the top of some of the text files included the title and author of the book and the publisher information.
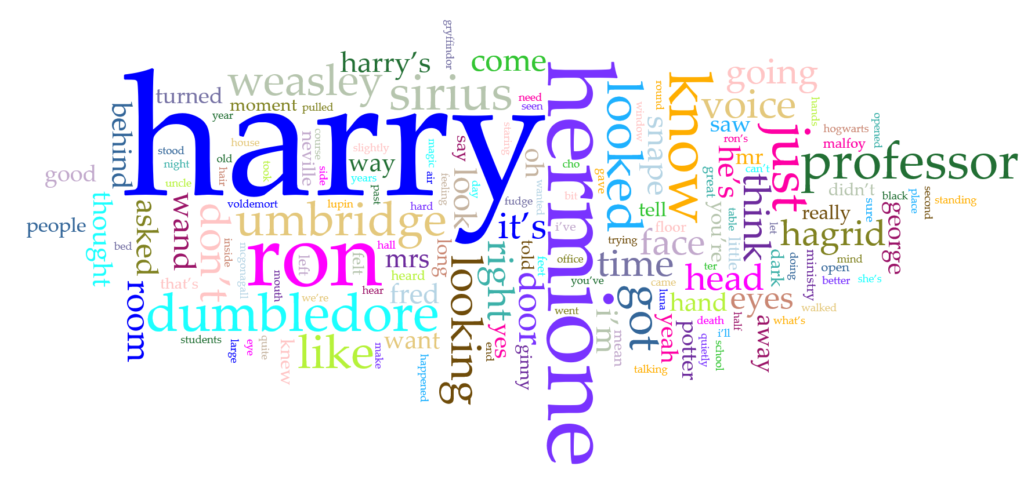
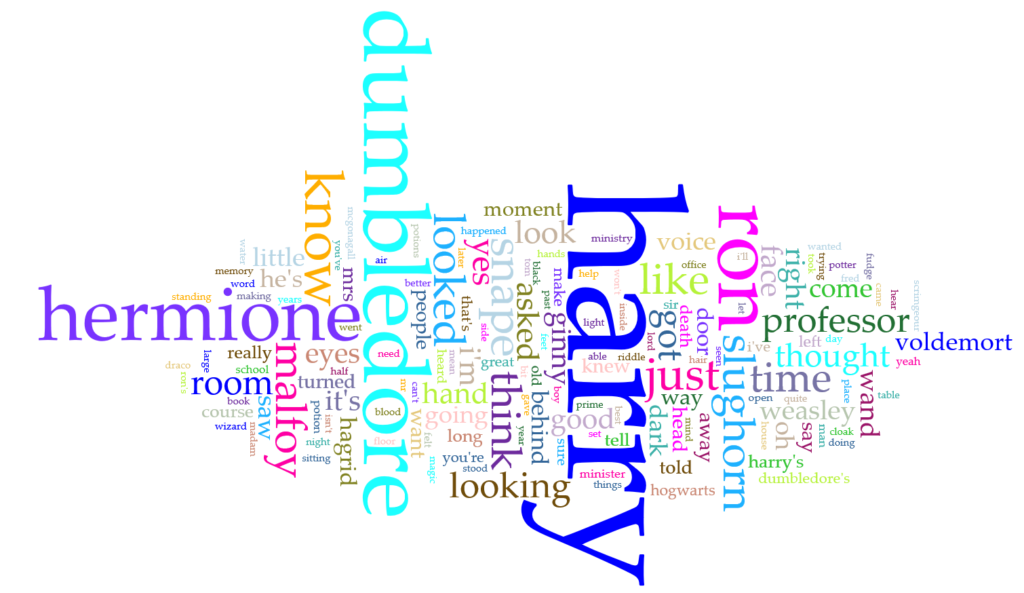
Once that was done, I uploaded each text file into Voyant and just tried out as many of the tools as I could. One of my favorites has always been the Word Clouds, or Cirrus as Voyant calls it. I created a 155 word cloud for each book separately as well as the corpus as a whole.
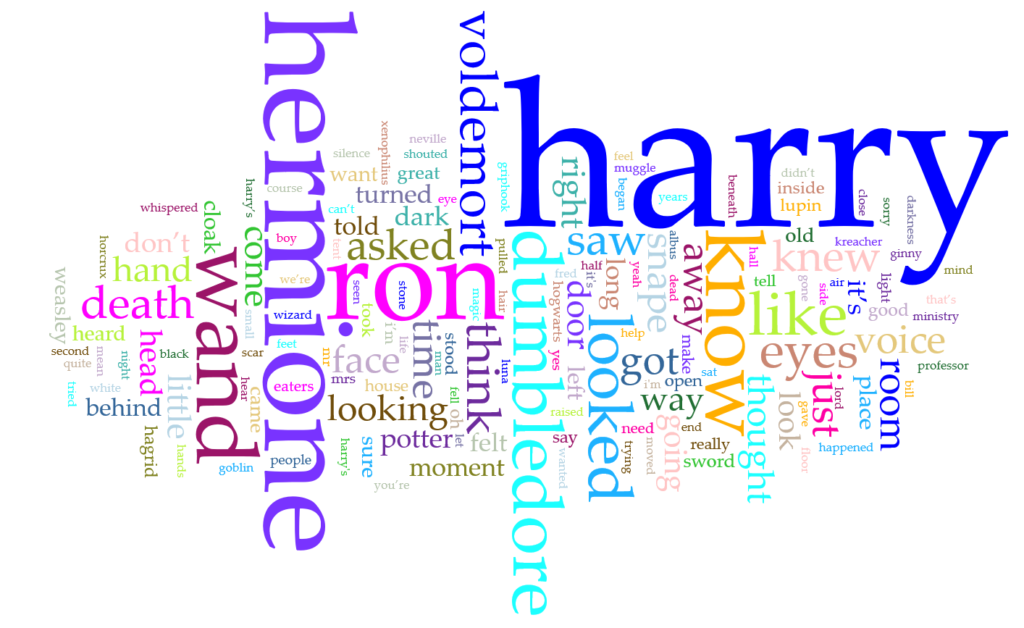
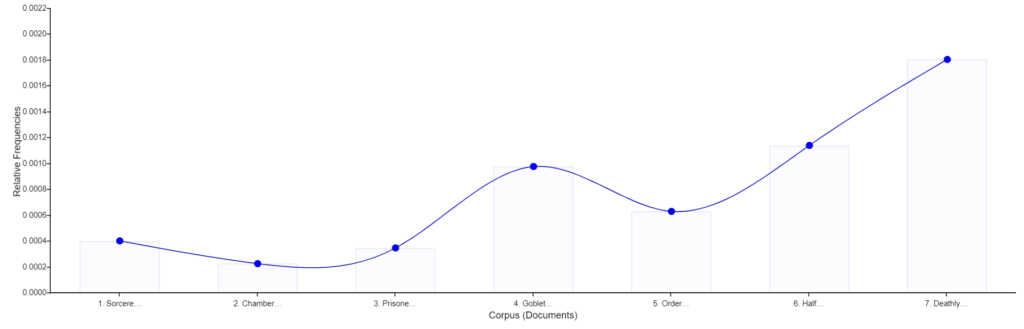
One item that stood out to me right away, which is obvious from knowing the content of the books but was still interesting to see, was how Voldemort’s name was used the most in the last book, “Harry Potter and the Deathly Hallows”, compared to all of the other books. This makes sense when understanding that the last book is when Voldemort is the most present and where people are more willing to say or think his name compared to the other books.
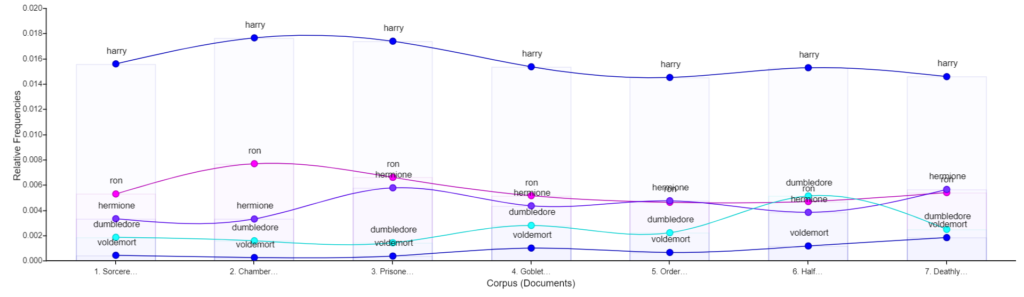
After this I wanted to see the trend of Voldemort’s name across the corpus.
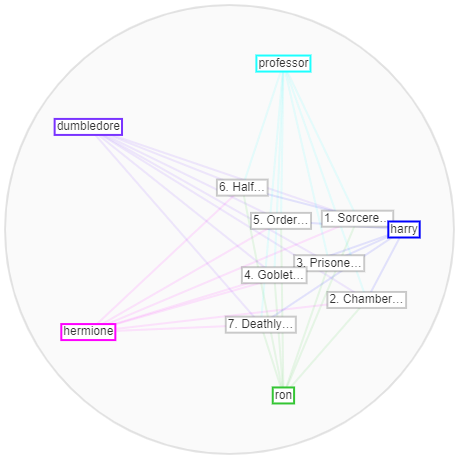
Then, after seeing this, I wanted to see the comparison between his name and the other main characters in the series. I didn’t realize that I could add labels at first but, when comparing to the other characters, it was necessary in order to tell them apart.
There were a few things that I noticed when I was first experimenting with the word cloud. One thing was that the largest or second largest word originally was “said”. This was obvious as the book is set in third person. However, I did not want to include “said” in the findings, so I was able to use Voyant’s edit feature to exclude “said” from the corpus. There were many other words that I wish I could have excluded as well but it would have taken a lot of time to go through it all. One other thing that I noticed in a few of the word clouds (such as the corpus one) is that there must have been typos in a few of the text files because “harry’s” and “harry’ s” showed up twice (there is a space between the apostrophe and the “s” which is making them count as two separate words. Of course, it was bound to happen when relying on text files put together by others.

I took some time to mess around with other tools and I have included screen shots below. One of which looked at the location that a word(s) show up in each text file. When looking at the use of “Harry”, what jumped out at me was the gaps that can be seen at the beginning of the Sorcerer’s Stone, Goblet of Fire, Half Blood Prince and Deathly Hallows.

Of course, with knowing the story, the start of each of these books begins with a chapter or two that do not focus solely on Harry.
Below are other items that I pulled from Voyant in case you are interested. There is so much that can be done with this information, I am sure.