For the final project I knew I wanted to do something with the archives. I was also inspired by the Puerto Rico Syllabus project and wanted to incorporate a pedagogical element. There are projects that focus on either archives or pedagogy, but very few that focus on both. My concept for a Steinway Family Digital Archive had multiple goals: to consolidate materials related to the Steinway family into one place, provide a space for educational materials that use the archive, and have the space be collaborative so educators, students, and researchers can build materials together.
I have worked on an archival digitization project before, so I know that it takes a lot of time. Trying to come up with a project that fit into the tight timeline of a semester forced me to reevaluate the scope of the project. Instead of digitizing materials, I would focus on collecting materials that have already been digitized and to only focus on New York City institutions. Also, since I don’t have much experience with teaching or using education materials, I left that part of the project open for the next iteration. Most of the my proposal clarifies that I’m laying the groundwork for a future version of the project that will incorporate more archival materials and educational materials.
I haven’t done any text analysis work before so I decided to use Voyant since that was marked as the easiest tool to use. The Voyant home page doesn’t have a lot of options to see without text, so I put in the text to The Iliad to see what the output would look like.
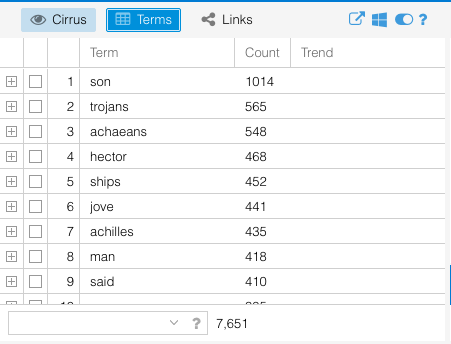
Results for the Iliad in Voyant
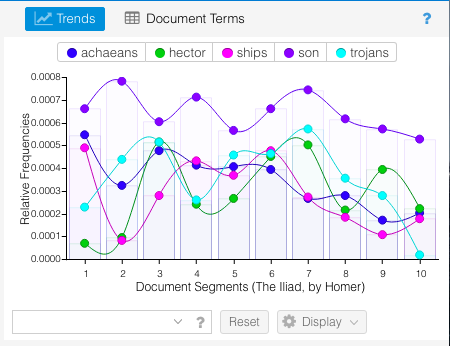
I chose The Iliad because I have read it multiple times and figured it would be a good baseline to test out what Voyant could do when I had a default skin of a corpus. I used the Voyant guide to go through the different sections at the same time that I had the The Iliad corpus open. I focused particularly on the terms list available in the Cirrus window – which also offers a nice word cloud visual – and the Trends window.
Terms view
Trends view
I was looking through some of the sample projects while trying to decide what to do for this project and saw one that analyzed a group of tweets from Twitter. It reminded of a New York Times article that came out a few weeks ago about NYT reporters that went through all of Donald Trump’s tweets since he became President and thought that would be an interesting experiment for this assignment. As it turns out there was an the accompanying Times Insider article that linked to a website called TrumpTwitterArchive.com (spoiler alert – they already constantly update analyses of his tweets) that also explained how they got their data.
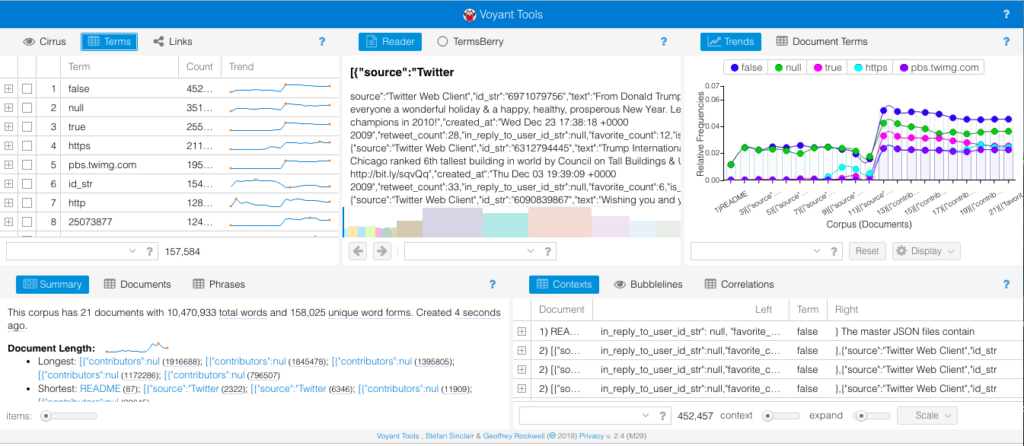
Unfortunately, Voyant couldn’t display the data when important directly from Github – apparently JSON is still experimental – and ended up trying to analyze the source code instead of the text in the tweets.
Default skin results when using JSON files
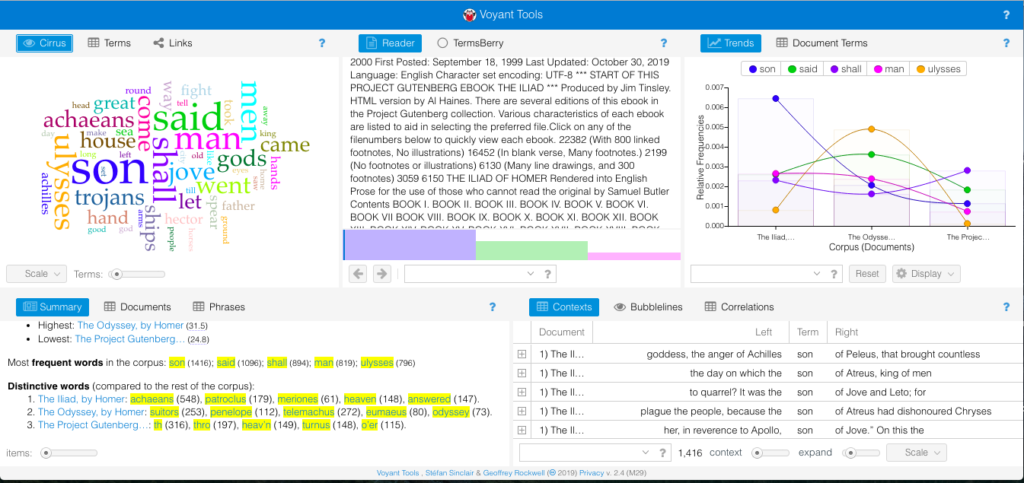
I did a search to see if anyone else had an open data set of Trump’s tweets that were in a format that Voyant could recognize but found nothing. I think this particular idea needed a tool that had more flexibility with its capabilities and user with the necessary skills and knowledge to pull it off. I still wanted to play around with a larger corpus, so I turned back to the Classics theme I had in the beginning and put in the The Iliad, The Odyssey, and The Aeneid. All of them are very well known historical epic poems written by Homer and Virgil. The default skin came out like this:
Default skin comparing The Iliad, The Odyssey, and the Aeneid
I don’t think the Summary told me anything that I didn’t already know. The Iliad and The Odyssey were both written by Homer much earlier than when Virgil wrote the The Aeneid. Given the difference in authors and time period, it makes sense that the first two epics were longer in length and had longer sentences. The Aeneid was shorter, had a higher vocabulary density, and the distinctive terms were much different than the other two (which could also be contributed to the translation). One thing I really enjoyed was the visual representations of the texts – particularly the bar graph of top words in each book.
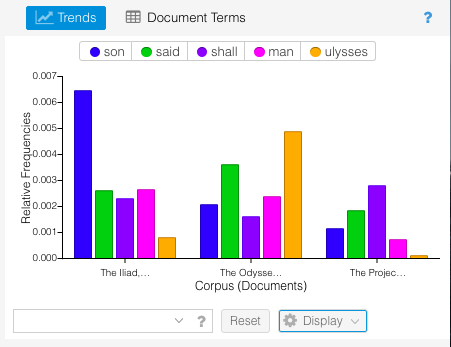
Trends box with column display
This breakdown visually showed connections about the poems that I wouldn’t have otherwise though of. For example, “son” appeared exponentially more in The Iliad than the other two epics. This is because characters are always introduced according to their family lineage – for example “Achilles, son of Peleus.”
Since The Iliad described the events of the Trojan War, there were a larger number of characters as Heroes from many Greek cities joined the war effort against the Trojans. The introduction and description of the actions of these characters means there were many more “son of…” statements than in the other poems. Similarly, the Odyssey was the story of Odysseus’s journey home from the Trojan War, so naturally that would be the dominant word from that poem. These are connections I wouldn’t have naturally thought of when comparing the two epic poems. Overall, I can see why Voyant is the easiest text analysis tool, but I feel like this could be somewhat limiting to others who may have more coding skills and are able to utilize a wider variety of file types. Comparing these texts in this way though did visualize trends that I haven’t thought of before, and I have gone through these texts multiple times for my minor in undergrad. This exemplified what our readings noted about how distant reading doesn’t replace close reading, but creates a space where new and different questions can be asked.
Here’s the link to Project STAND I mentioned last night in class in case anyone is interested. After looking at it more closely, the project is aimed at creating a central repository for archival collections focused on student activism on college campuses. Although there are more current movements (there’s a few Twitter Archives), there’s also links to collections and finding aids from 1960’s to present.
I’ve seen a few of these types of archival projects where a central repository is chosen to host related collections and materials. The Puerto Rico Syllabus project noted it could be enhanced “by the inclusion of primary texts and historical documents…” so I, personally, feel like the natural next step would be to combine the two project models.
On Tuesday I went to Digital Initiatives workshop on using on using Omeka.net. I’ve only ever interacted with Omeka as a user and didn’t have any experience using the platform. The presentation slides are on the Digital Initiatives website.
Omeka is a content management system (CMS) and publishing platform that is used by many archives, historical societies, and libraries to build digital exhibits and small collections of objects. Omeka focuses more on metadata than WordPress so it’s a good option for collecting higher amounts of data and still being able to organize and present themes and narratives. The presenter went over concerns that should be thought about before choosing a CMS for a project such as:
metadata standards – what metadata standards do you want to use when importing your digital objects. Omeka defaults to Dublin Core but it can be customized
file formats – what file formats will be included? There are standards for file formats that you should think about, and this will also help you manage your storage i.e. a TIFF will require more storage than a jpg
information architecture – how do you envision accessibility and discoverability of your project
rights and permissions – do you have the rights or permission to use all the objects that will be used in your project?
sustainability – do you have the time to manage the project and update it when there are new versions of files available or to check compatibility with new media
The next part of the workshop was going through and using our test site to look at the different ways Omeka can be customized (we didn’t use Omeka S because of the cost and the extra features weren’t relevant for an introductory workshop), added individual items to the sites, and created a collection. The collections are comprised of items that are specifically curated to express a theme or narrative. I really liked the comparison that presenter mentioned where the items held in Omeka are the archive, but the collections are similar to pulling items out of the archive for a museum display.
Overall, the workshop was pretty easy and I found Omeka to be pretty accessible. I’ve used more complex CMSs tailored specifically for archives, so a lot of the interface looked pretty familiar. There was mention of an advanced Omeka workshop in the Spring that will focus creating exhibit and focus a bit on sustainability. The exhibits was the portion of Omeka I was particularly interested in so I’m looking forward to that.
My goal when approaching this assignment was to find a mapping platform that I could apply to projects at work. I work at a small history archive in Long Island City that focuses on New York City political and Queens local history. I’ve seen some archives that have developed geotagged photos to show what a specific building or street looked like at a different point in history, or some have developed “walking tours” where users can follow a predetermined path to see historic sites and have relevant photos or material displayed when they get there. While reviewing the options in “Finding the Right Tools for Mapping,” I wanted to choose something that was free and accessible for someone with limited technical skills (ahem, me). I also wanted something that had at least some interactivity instead of a static map. I first skipped over the section on ArcGIS Desktop because it’s listed as proprietary and not very beginner friendly, however, one of the strengths lists ESRI’s Story Maps which I thought would create a neat linear display that would be great for creating a historic walking tour using archival materials.
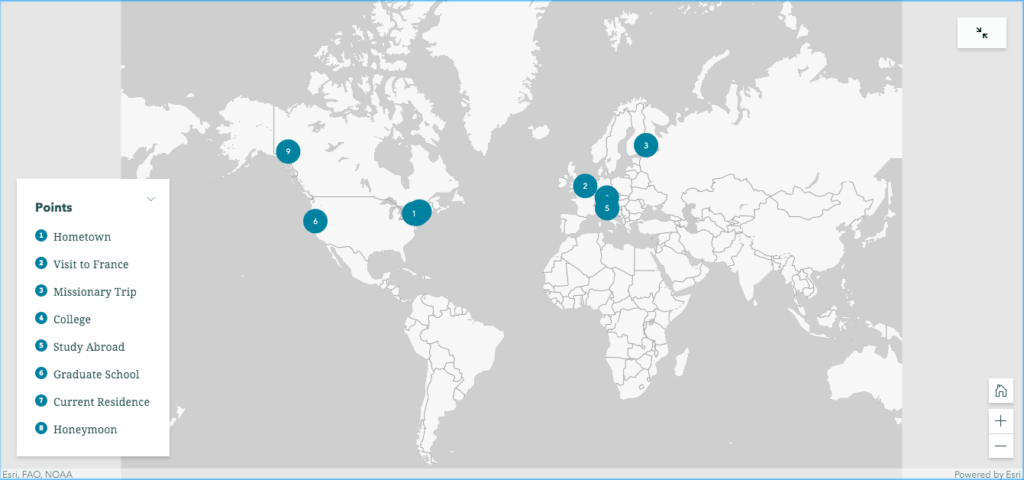
Since we only had two weeks to put together a map, I didn’t have time to do the necessary research to put together an actual walking tour using my archive’s materials – so I created a map based on various places relevant to my life i.e. where I attended school, a semester abroad, honeymoon, etc. At first, I followed the link directly to the ArcGIS Story Maps page and quickly found the classic StoryMap page and found that one to be more accessible. I created a free account and created a map with nine data points.
Original Story Map
I plotted the points but quickly realized that the map was more static than I would have liked and didn’t have the easiest navigation between the data points. It did provide more information once you clicked on one of the data points, but I felt that this would be a better option if it were embedded into a webpage or online exhibit. I looked up a few tutorials and found Story Map Tour. By this time, I had latched on to the “walking tour” idea and was looking specifically for a map that could move through the data points in a more linear fashion. The StoryMap Tour seemed to be catered for that design.
Creating the map: the interface for creating a story map is very user-friendly and offers a lot of options for getting your data points on the map. Images and video and can be attached to the data points of which can be imported via Flickr, Youtube or CSV file. I didn’t have enough data to attempt a CSV import, but I have reservations about the level of detail needed to capture the information and plot it on the map automatically. I also wasn’t thrilled about having to use proprietary sites to import media content, but I used so Creative Commons images to add a visual element. When importing via Flickr – I had to manually plot the points which became very time consuming. Points could also be added using a URL to media and the latitude/longitude coordinates, however, that is also only able to be done one by one and could become time consuming.
Customizing the map: there a few features that allow you to customize from predetermined choices. The data pointers come in four different colors, there are 24 options for the base map, there are 3 layout options, and a title and header section that can be customized to include a custom logo or link to a specific web page. While this may be limiting to someone who’s technical knowledge with mapping/GIS software – it worked for my needs. I was also impressed with the how close the view would zoom in onto the map which would make manually plotting points much easier. After I plotted my nine points, I went through and give each data point a title and short description. For the 9th point, I filled the description box with lorem ipsum text to get a sense of how much content could be included.
Overall, I was trying to experiment and test the features of Story Maps Tour – with the idea of a archival-based walking tour in the back of my mind – and feel comfortable that I would be able to put something together. My next step would be to attempt importing a larger data set from a CSV file in order to really test the limits. However, for smaller, more localized projects I think Story Maps is a perfectly adequate tool for beginners with limited skills and limited budget.
I’ve been looking forward to this week’s readings since the intersection of DH and the Archives is what I’m most interested in. However, in an effort to be totally transparent, I found myself reflexively being defensive when reading through Daut’s article the first time – there’s a history of archivists struggling to be recognized as professionals in their own right – and had to reread with a conscious effort to keep an open mind in case my own bias was keeping me in an old pattern of thinking.
In terms of access, I think Daut framed her discussion of decolonizing archives and repatriating Haitian documents in a way that exemplified discussions that archivists are having. I think in most disciplines there is a push back against the white/straight/male version of history that is commonly reflected in archival holdings and there has been a real effort in recent years to include materials that more accurately reflect a realistic historic record. I’m also glad she included Revue de la Société Haïtienne d’Histoire, de Géographie et de Géologie in her discussion about digitization. It echoes the same sentiments that was expressed in “Difficult Heritage…” from last week’s readings. Just because there are documents that can be digitized and available universally, it doesn’t mean that ethically they should.
I couldn’t overcome my bias during Daut’s discussion in the “Content” section as she advocates avoiding the “citizen historian” or crowdsourcing model in regards to digital scholarship and working with the materials. She says “Without a doubt, neither trained archivists nor traditional historians can be replaced in digital historical scholarship.” However, she continues on to discuss the contributions of “historian archivists” which itself diminishes the expertise and training of professional archivists. I think there is a clear difference in being trained to recognize and describe meta/data from documents and being a subject expert (historians) on the content, but both are needed in order to to fully engage with the data presented. This is a discussion that comes up from time to time in the archives profession and something I wanted to mention, but I do not want to devote too much space in this post to it.
Daut’s discussion on curation and context is a mixed bag for me, and I believe its because the term “archive” means something different to me. When Daut mentions that “Digital archiving projects…teach the reader/user the significance and importance of a defined set of documents…” that seems more like a digital project than an archive. By having a creator limit the documents that are used, it might restrict information that could potentially contribute to scholarship. The large amount of materials available in an archive (hopefully) means that no matter what question a researcher is trying to answer they have the resources to do so. That being said, I think that deeper evaluation of archival sources can contribute meaningfully to scholarship. In the case of Digital Aponte, a space was created for the absence of archival material. I thought the Digital Aponte project was a great way to carve out space for a gap in the archival record and to compile secondhand accounts in an effort to recreate some of what was lost. I particularly liked the interdisciplinary nature of the website and how there were sections devoted to genealogy and mapping, all while allowing annotations to encourage collaboration across multiple disciplines. Trying to center and create an environment that resembled Aponte’s Havana also adds necessary contextualization. I’m excited to hear Ada Ferrer’s description of the project during class.
The readings this week were an introduction to me on both Digital Humanities and Caribbean Studies (I use this broadly and for a lack of a better term) since I haven’t had any in depth experience with either field. I decided to keep my reflections about the individual sites to a top level impression as I’m interested to see the varying viewpoints that are brought to the table.
The Torn Apart/Separados project as mentioned in “A DH That Matters” in the 2019 Debates in the Digital Humanities this project is an example of how the Digital Humanities can be used to ally with activists and create projects that will use data to “amplify the voices of those most in need of being heard.” The project is very rich in data and offers visual representations of the flow of money through ICE in the past few years thereby shedding light on individuals and companies that keep immigrant detention centers running. The three Debates in the Digital Humanities introductions demonstrated how the field has evolved since 2012 – growing from a very new field trying to define itself and what being a digital humanist means (2012), to becoming more established but still wrestling with what the field’s focus is (2016), and currently being able to expand beyond the – albeit very broad – definition of DH projects to partner with outside fields (2019).
The Create Caribbean site has a list of DH projects that focus more on pedagogy and educational materials as opposed to strictly research orientated projects. In terms of the Caribbean, this most reminded me of the section “The Challenge of the Digital Black Atlantic” in the Digital Black Atlantic Introduction. Josephs and Risam discuss the difficulties of marrying Caribbean/black studies and digital humanities, one example which is systematic barriers such as the lack of opportunities to learn digital skills, such as coding, in order to participant in scholarship. Create Caribbean offers the Create and Code program which addresses this issue by fostering digital literacy to students in Dominca and is an example of trying to close this gap.
Finally, The Caribbean Digital did not seem to link to any DH projects (unless I missed them?) but gave descriptions about the different panel discussions. The workshop on Digital Decolonization was presented by two panelists from Northwestern who referenced the Early Caribbean Digital Archive which we also needed to look through. I have to admit, as an archivist, I was most excited to look through this site, however, in terms of archival theories and best practices it left me somewhat confused. This particular site will take longer to unpack for me personally which is beyond the scope of this post. In terms of how it related to the readings, the ECDA is another example of DH pedagogical tools since there are resources for teachers, exhibits based off of the archive, and examples of student projects. I looked through the exhibits and most of the content is based off of Western European materials and wonder how much of the narrative produced challenged the Eurocentric view of history in the Caribbean, or if this is solely based on a lack of available materials.
Need help with the Commons?
Email us at [email protected] so we can respond to your questions and requests. Please email from your CUNY email address if possible. Or visit our help site for more information: