
Objective:
I created .txt files of news reports about the 2019 Chilean uprisings from various sources in order to collect word frequencies for each. Within the .txt files I’ve removed article titles, working only with the body of the report in order to avoid internal repetition and pull word counts most accurately reflecting the content of the news story. This may be unwise however, as it could be suggested that the words appearing in the article headings are worth including in the count. This deserves more consideration, but either choice should not disrupt the experiment too much.
Sources to be used:
The Guardian – mostly direct quotations from demonstrators.
Al Jazeera – regarding a UN commission to investigate the situation in Chile.
Reuters – simple ‘who/what/where/why’ report.
When first running the code, I tested only The Guardian
report. To my dismay, the 10 most common
words appeared as:
the : 65
and : 51
to : 35
a : 26
in : 25
of : 25
have : 25
is : 20
i : 19
that : 17
The code worked, but not as planned. With my limited knowledge of programming, I think this indicates that I must adjust my stopwords list.
The next batch is slightly better but still missing the mark. 10 most frequent words are:
are : 17
people : 16
we : 15
for : 14
– : 11
my : 9
they : 9
has : 8
it : 8
want : 8
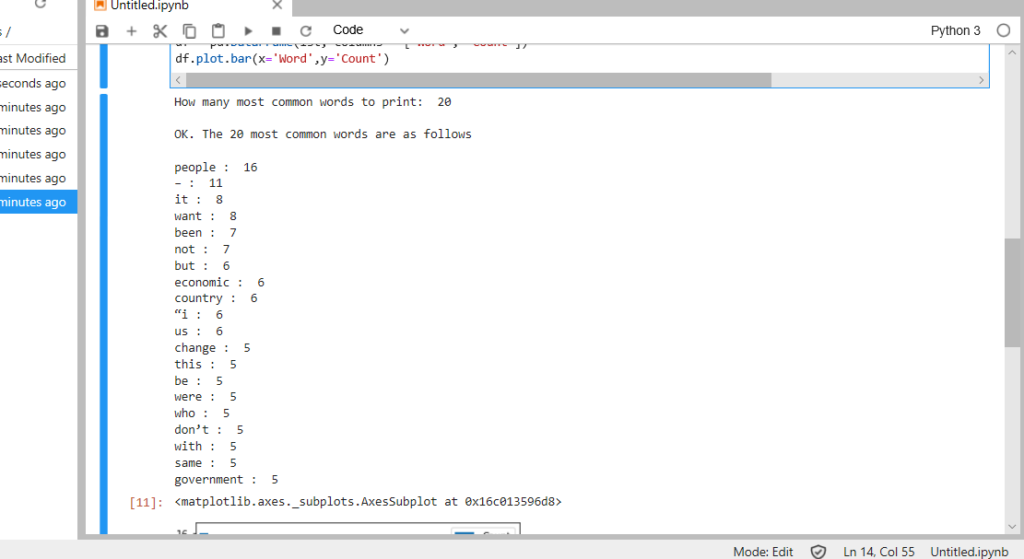
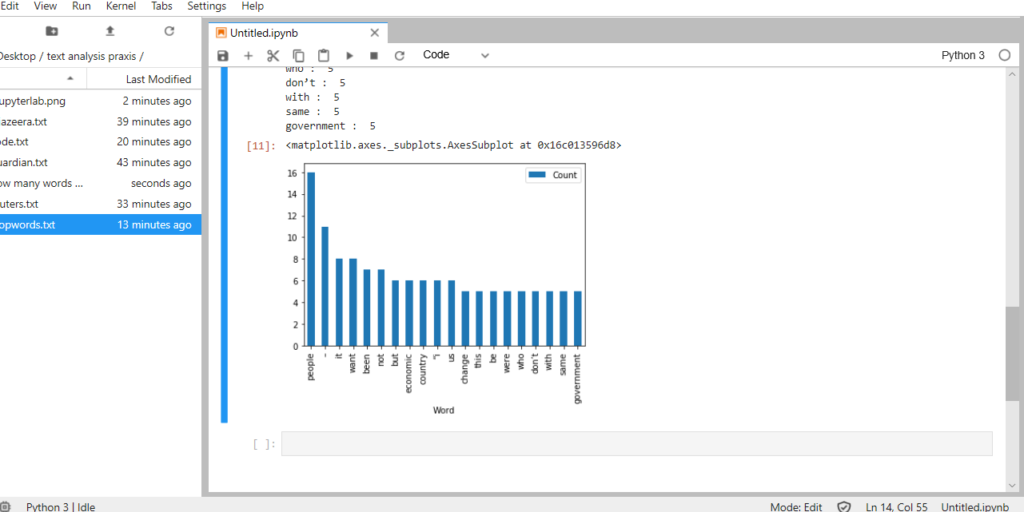
Again, I amend my stopwords (allowing ‘people’ to remain because I imagine it significant) and again the results improve but fall short. This time I request the 20 most frequent, to see how far along I am. Individual word frequency has now dwindled to the extent that they do not appear noteworthy:
people : 16
– : 11
it : 8
want : 8
been : 7
not : 7
but : 6
economic : 6
country : 6
“i : 6
us : 6
change : 5
this : 5
be : 5
were : 5
who : 5
don’t : 5
with : 5
same : 5
government : 5
Conclusions:
It strikes me that this frequency measurement has not provided a significant assessment of content. This is likely due to the size of the corpus, yet another concern looms foremost. In the decisions I made regarding my ever-expanding stopword list, I’ve noted an ethical concern – that as the programmer determines what words are significant enough to count (ex: my decision that ‘people’ was not worth adding to the stopwords), they may skew the results of the output dramatically. This is my most important takeaway.
What a great and timely topic, Matt. Your conclusion reminds me of the “All Models Are Wrong” piece; it’s knowing what our models might not be showing that is often the prompt for the next iteration.
Like you, I found that word frequencies alone, even with manipulation, didn’t offer much meat, so I’ve turned to tf-idf (term frequency – inverse document frequency), and my early play with it is yielding, for me and my particular texts, some interesting stuff. I used a Programming Historian tutorial to get started, but the code has errors, so if you’d like a copy of my working version I’m happy to share it.
Thank you for your comments, Kelly. I will look into tf-idf methods.
Also thanks for the offer. I would certainly like to see the code you’ve corrected – I’m sure your work could teach me a thing or two.